[알림 기능 찾아 삼만리 Day 6 링크]

현재 구현한 이메일 스케줄러는 다음과 같은 문제가 있었다.
(1) 한 스케줄러가 데이터 조회와 이메일 전송 두 가지를 모두 담당한다.
현재 스케줄러는 데이터를 가져오고 그 데이터를 바로 이메일 전송에 활용하는 구조인데, 만약 이메일 전송에 시간이 오래 걸리면 스케줄러가 다시 작동할 때 작업이 서로 겹칠 위험이 있었다. 이 문제는 특히나 이메일을 대량으로 전송해야 할 때 더욱 심각해질 수 있었다. 현재 @Async 어노테이션을 사용하지만, 한 번에 많은 작업을 처리하는 데 시간이 오래 걸리면, 스케줄러의 데이터 조회와 이메일 전송 작업이 서로 충돌할 수 있었다.
(2) 조회해 온 데이터를 저장하는 로직이 없다.
현재 스케줄러는 조회된 데이터를 바로 전송하는데, 데이터를 저장하는 로직이 없기 때문에 데이터를 나중에 처리하거나 재사용할 수 없었다. 예를 들어, 이메일 전송에 실패하거나 네트워크 장애가 생기면, 전송에 실패한 이메일을 다시 보낼 수도 없었고 이미 한 번 조회한 데이터를 다시 조회해야 하는 문제가 발생했다. 이 문제를 해결하려면 조회한 데이터를 저장할 곳도 만들고, 필요할 때 이메일 전송을 재시도할 수 있는 구조로 스케줄러를 리팩토링(refactoring)해야 했다.
(3) 이메일 하나 보내는 데 시간이 너무 오래 걸린다.
현재 이메일은 구글 SMTP 서버로 전송되는데, 외부 서버와 통신이 필요하다 보니 응답 속도가 꽤 느렸다. 이제 실시간 알림 기능도 구현할 예정이고, 그만큼 시간 단축이 중요한 만큼 다른 서버를 활용하든, 이메일을 보내는 데 얼마나 걸리든 다른 작업이 영향받지 않도록 해야 했다.
이 외에도 이메일 수신자 주소가 올바른지 검증하는 로직도 추가되고, 나중에는 조회해올 데이터가 더 늘어날 수도 있는데, 현재 스케줄러는 확장성과 유연성이 모두 떨어졌다. 이런 이유로 가장 먼저 스케줄러에 욱여넣다시피 한 로직을 분리하기로 했다.
이때 마치 퐁실퐁실한 빵 반죽을 분할하기 전 고민하는 제빵사처럼 어떻게 나누어야 좋을지 또 고민이 들었다.
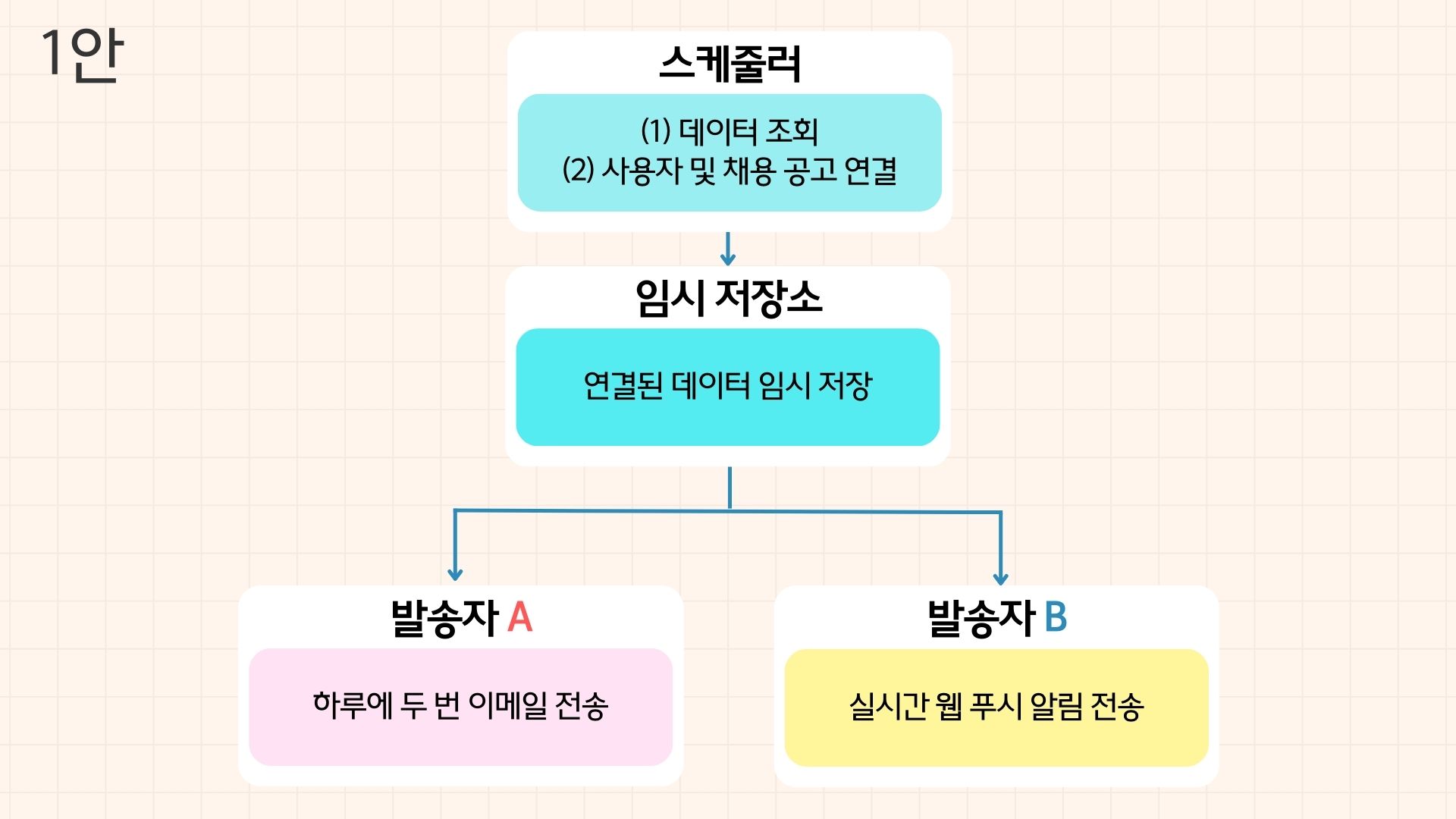
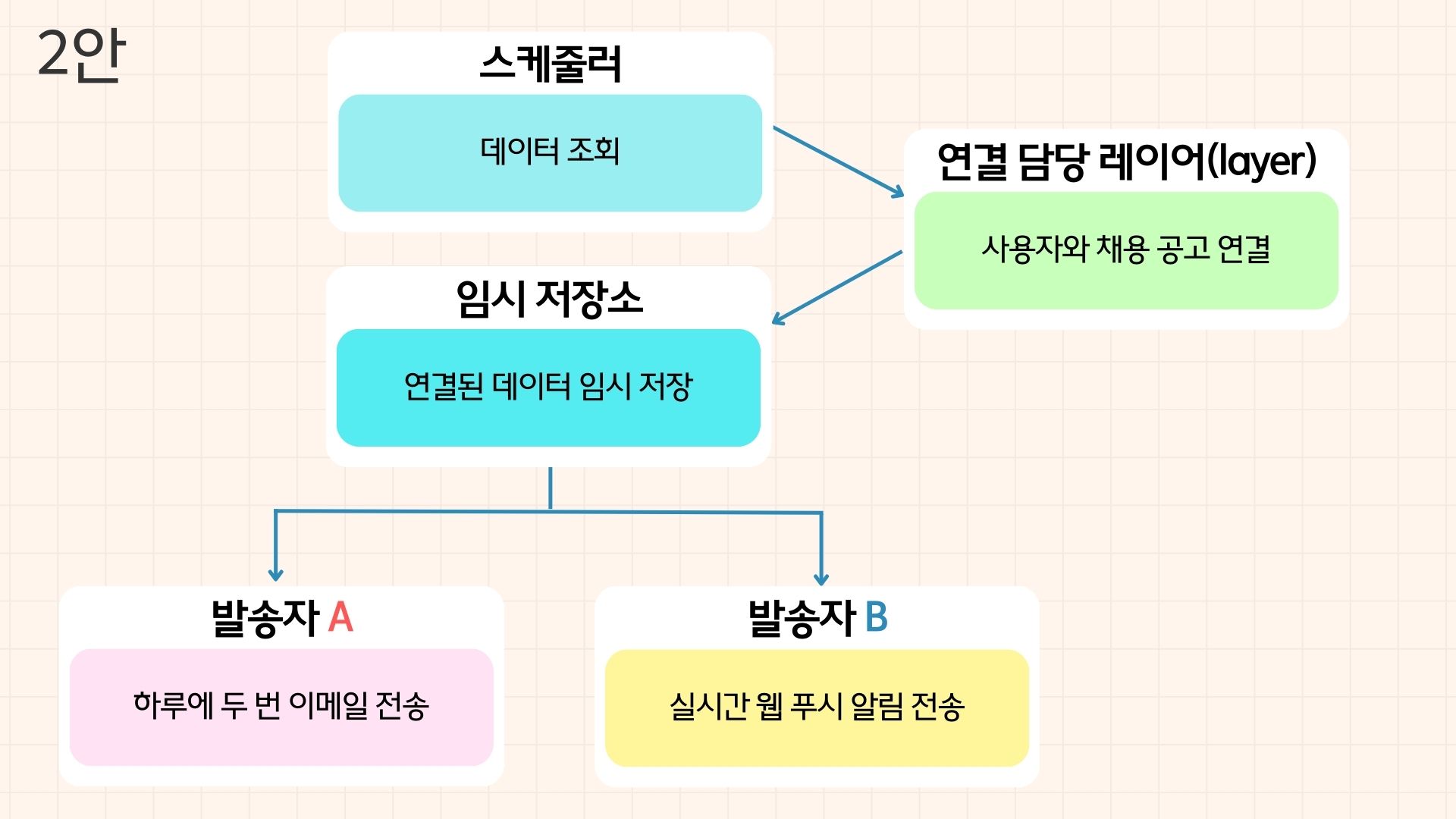

고심한 끝에 2안을 골랐다.
첫째, 채용 공고 데이터와 사용자 데이터가 늘어나면 스케줄러에 부담이 커질 듯했다.
둘째, 지금은 연결 방식이 똑같지만 나중에는 알림 유형별로 달라질 가능성이 있었다.
셋째, 데이터를 연결하는 로직을 별도로 분리하면 다른 곳에서도 재사용할 수 있었다.
2안을 고르고 나니 자연스레 다음 고민이 이어졌다.
'그래서 임시 저장소는 MySQL을 그대로 쓸까, 아니면 다른 저장소를 찾아야 하나?'
Day 9에서 계속…….