'어떻게 채용 공고 목록을 가져오지?'
이메일 전송 기능을 구현하기 전에 우선 사용자가 등록한 기술 키워드가 포함된 채용 공고 목록부터 조회하기로 했다. ERD(Entity Relationship Diagram)을 바탕으로 조회 순서를 고려한 뒤, 저번 프로젝트에서 사용한 스프링 스케줄러(Spring Scheduler)를 활용하기로 했다. 이 기술에 익숙했에 빠르게 기능을 구현하고 성능 개선에 집중할 수 있을 듯했다.
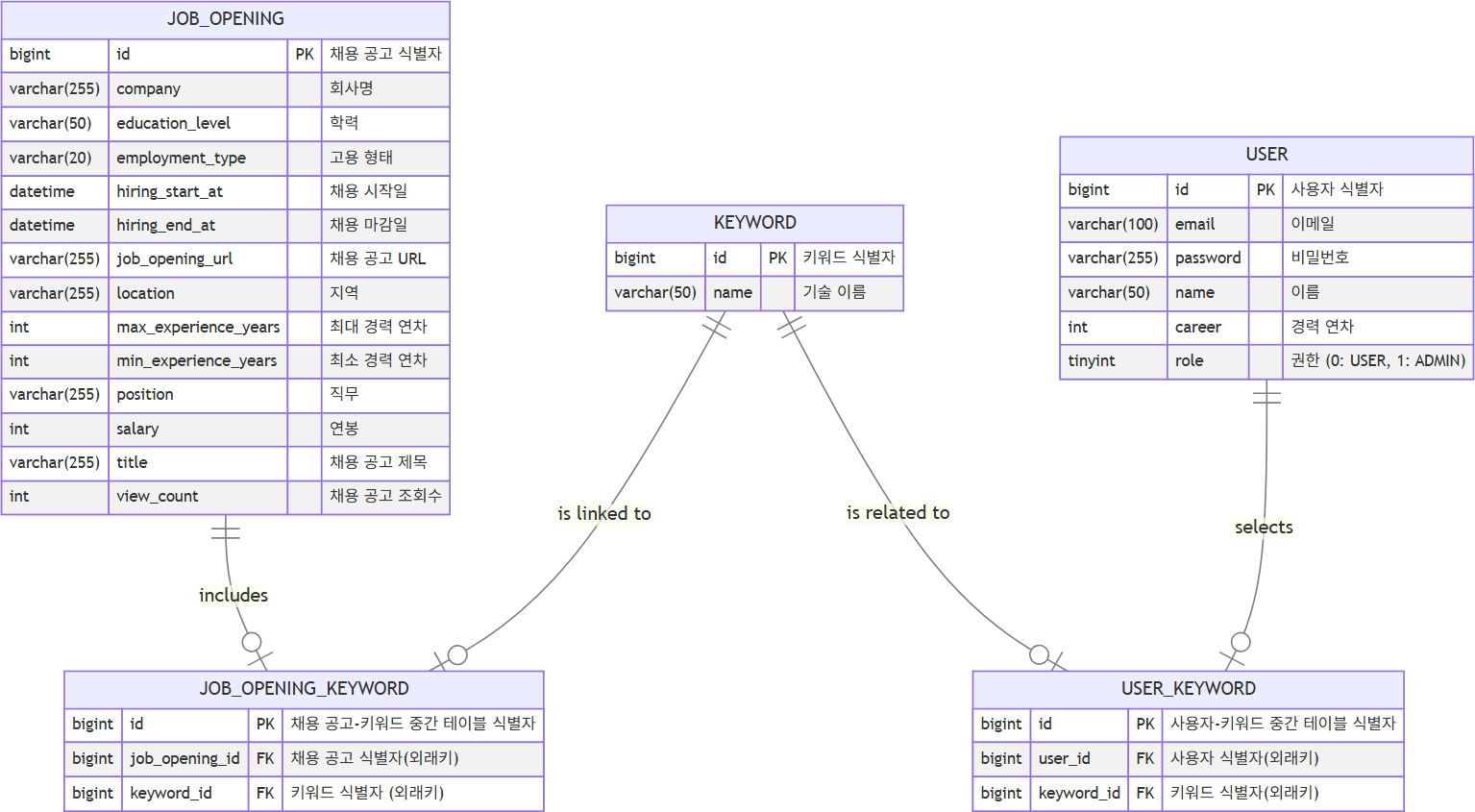
(1) UserKeyword 테이블에서 사용자가 등록한 키워드 식별자 목록 조회하기
(2) JobOpeningKeyword 테이블에서 해당 키워드를 포함한 채용 공고 식별자 목록 조회하기
(3) JobOpening 테이블에서 조회된 채용 공고 정보 조회하기
전체 흐름을 머릿속으로 정리한 뒤에는 스프링 스케줄러(Spring Scheduler)를 사용하고자 애플리케이션(application)에 @EnableScheduling 어노테이션(annotation)을 추가했다. 그다음, 필요한 메서드와 스케줄러 클래스를 만들어서 30초마다 채용 공고 목록을 조회하도록 설정했다.
package com.project.cheerha;
import com.project.cheerha.common.properties.BcryptSecurityProperties;
import com.project.cheerha.common.properties.JwtSecurityProperties;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.data.jpa.repository.config.EnableJpaAuditing;
import org.springframework.scheduling.annotation.EnableScheduling;
@EnableScheduling
@EnableJpaAuditing
@SpringBootApplication
@EnableConfigurationProperties({
JwtSecurityProperties.class,
BcryptSecurityProperties.class
})
public class CheerhaApplication {
public static void main(String[] args) {
SpringApplication.run(CheerhaApplication.class, args);
}
}package com.project.cheerha.domain.user.service;
import com.project.cheerha.domain.user.entity.User;
import com.project.cheerha.domain.user.repository.UserRepository;
import java.util.List;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Component;
@Component
@RequiredArgsConstructor
public class UserFindByService {
private final UserRepository userRepository;
public List<User> findAllUsers() {
return userRepository.findAll();
}
}package com.project.cheerha.domain.keyword.repository;
import com.project.cheerha.domain.keyword.entity.JobOpeningKeyword;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
public interface JobOpeningKeywordRepository extends JpaRepository<JobOpeningKeyword, Long> {
@Query(
"SELECT jok.jobOpening.id "
+ "FROM JobOpeningKeyword jok "
+ "WHERE jok.keyword.id IN :keywordIdList"
)
List<Long> findJobOpeningIdListByKeywordId(
@Param("keywordIdList")List<Long> keywordIdList
);
}package com.project.cheerha.domain.notification;
import com.project.cheerha.domain.jobOpening.entity.JobOpening;
import com.project.cheerha.domain.jobOpening.repository.JobOpeningRepository;
import com.project.cheerha.domain.keyword.repository.JobOpeningKeywordRepository;
import com.project.cheerha.domain.keyword.repository.UserKeywordRepository;
import com.project.cheerha.domain.user.entity.User;
import com.project.cheerha.domain.user.service.UserFindByService;
import java.util.List;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
@Slf4j
@Component
@RequiredArgsConstructor
public class NotificationScheduler {
private final JobOpeningRepository jobOpeningRepository;
private final JobOpeningKeywordRepository jobOpeningKeywordRepository;
private final UserKeywordRepository userKeywordRepository;
private final UserFindByService userFindByService;
// 30초마다 스케줄러 실행
@Scheduled(cron = "*/30 * * * * *")
@Transactional
public void findJobOpeningListIncludingUserKeyword() {
// 모든 사용자 목록 조회
List<User> userList = userFindByService.findAllUsers();
// 사용자별로 처리
for (User user : userList) {
// 사용자 식별자 추출
Long userId = user.getId();
log.info("사용자 ID: {}", userId);
// 사용자가 선택한 키워드 ID 목록 조회
List<Long> keywordIdList = userKeywordRepository.findKeywordIdsByUserId(userId);
log.info("사용자 {}의 키워드 ID 목록: {}", userId, keywordIdList);
// 사용자의 키워드 ID와 일치하는 채용 공고 ID 목록 조회
List<Long> jobOpeningIdList = jobOpeningKeywordRepository.findJobOpeningIdListByKeywordId(keywordIdList);
log.info("채용 공고 ID 목록: {}", jobOpeningIdList);
// 채용 공고 ID를 기반으로 실제 채용 공고 데이터 조회
List<JobOpening> jobOpeningList = jobOpeningRepository.findAllById(jobOpeningIdList);
log.info("채용 공고 수: {}", jobOpeningList.size());
// 연결된 채용 공고 데이터 출력
jobOpeningList.forEach(
jobOpening -> {
log.info("채용 공고 URL: {}", jobOpening.getJobOpeningUrl());
log.info("채용 공고 제목: {}", jobOpening.getTitle());
}
);
}
}
}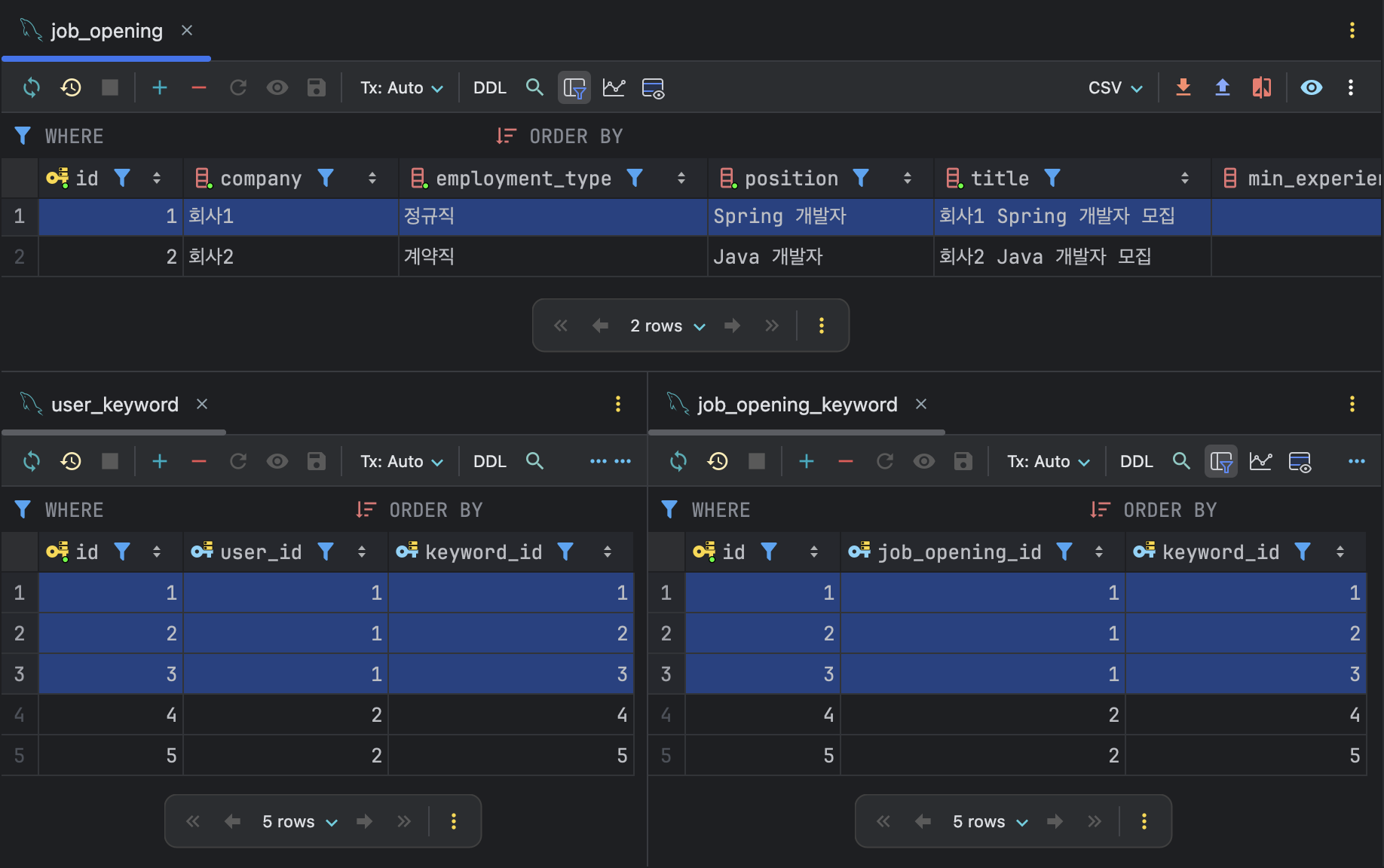
코드를 쓴 다음, 첫 테스트는 위와 같이 설정하고 결과를 예상한 다음 진행했다.
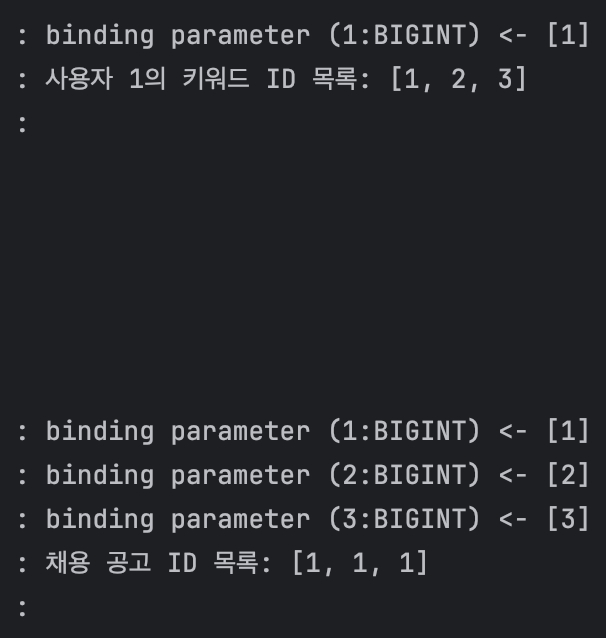
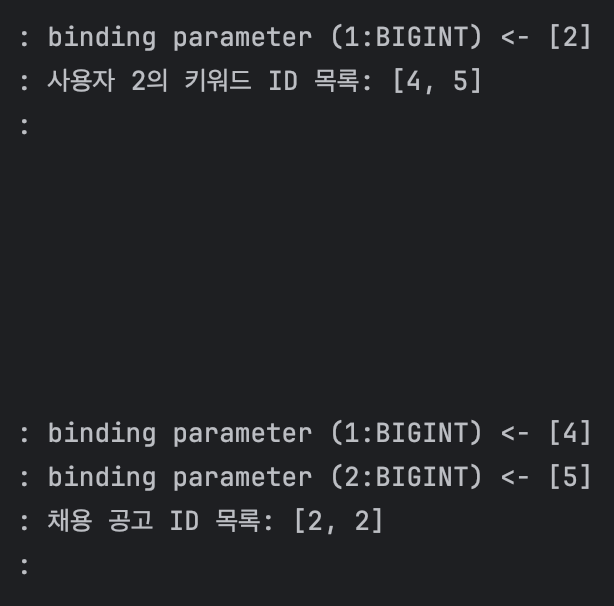
조회는 잘 되었는데, 로그 기록을 확인했을 때 조회된 채용 공고가 중복 조회되는 문제가 있었다.
package com.project.cheerha.domain.keyword.repository;
import com.project.cheerha.domain.keyword.entity.JobOpeningKeyword;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
public interface JobOpeningKeywordRepository extends JpaRepository<JobOpeningKeyword, Long> {
// [수정 전 Query]
// @Query(
// "SELECT jok.jobOpening.id "
// + "FROM JobOpeningKeyword jok "
// + "WHERE jok.keyword.id IN :keywordIdList"
// )
List<Long> findJobOpeningIdListByKeywordId(
@Param("keywordIdList") List<Long> keywordIdList
);
}package com.project.cheerha.domain.keyword.repository;
import com.project.cheerha.domain.keyword.entity.JobOpeningKeyword;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
public interface JobOpeningKeywordRepository extends JpaRepository<JobOpeningKeyword, Long> {
// [수정 후 Query]
@Query(
"SELECT DISTINCT jok.jobOpening.id "
+ "FROM JobOpeningKeyword jok "
+ "WHERE jok.keyword.id IN :keywordIdList"
)
List<Long> findJobOpeningIdListByKeywordId(
@Param("keywordIdList") List<Long> keywordIdList
);
}불필요한 조회를 막고자 쿼리(query)문에 'DISTINCT'를 추가했다.
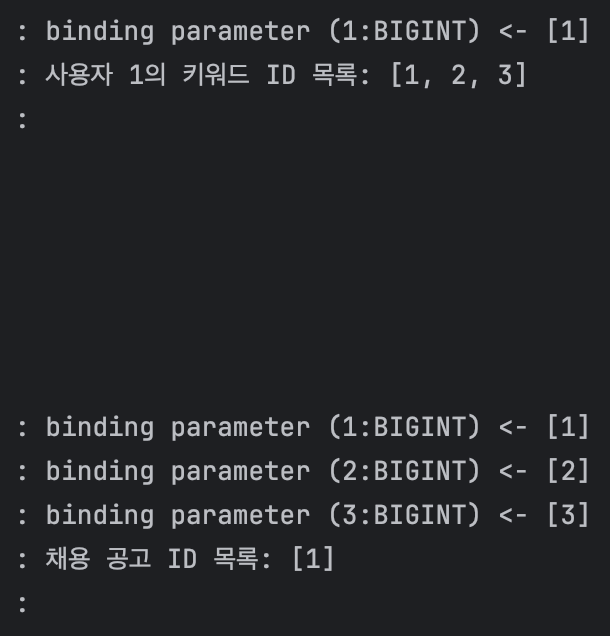
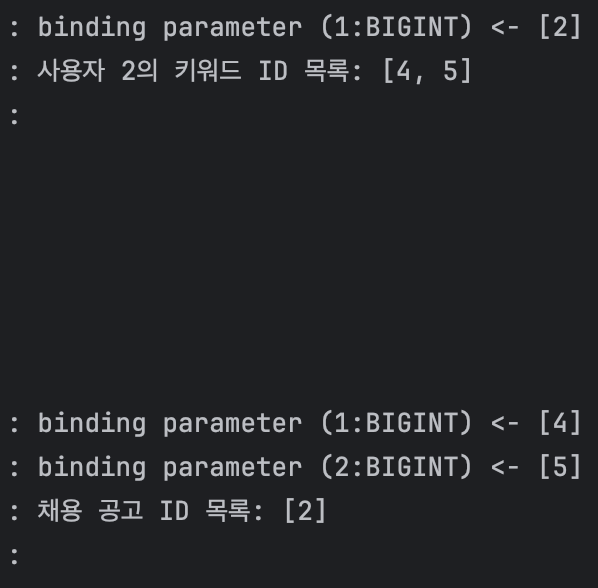
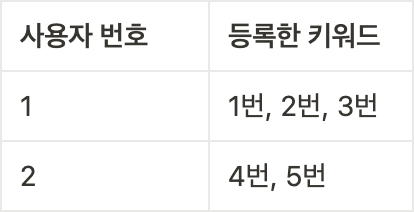
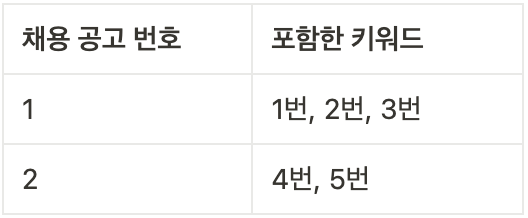
두 번째 테스트는 다음과 같은 조건에서 진행했다.
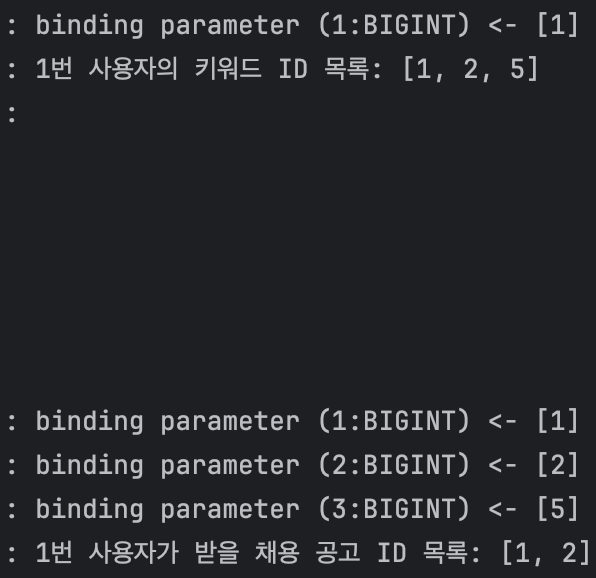

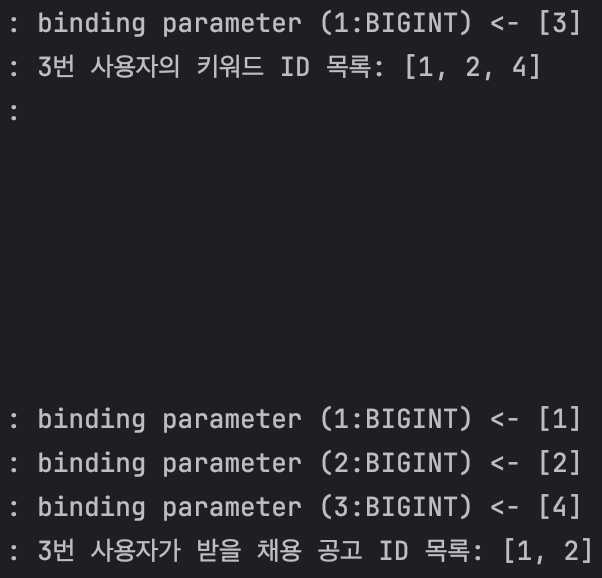
그 결과 원하는 대로 채용 공고 목록을 조회할 수 있었다.
문제는…….
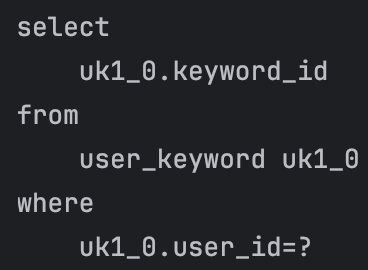
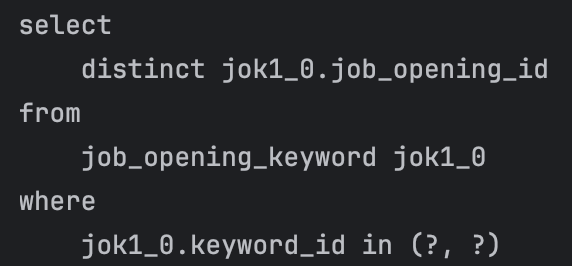
첫째, 사용자가 3명일 때 사진 속 쿼리문 3개가 3번씩 나갔다. 즉, 총 쿼리문 수가 9개였다. 지금 팀에서 사용하는 더미 데이터(dummy data)의 사용자만 2,000명이었는데, 현재 상태로는 총 6,000개 쿼리문이 나갔다.
서버 터지기 딱 좋았다.
둘째, 스케줄러가 작동할 때마다 이미 조회한 채용 공고를 다시 조회했다. 이를 개선하려면, 채용 공고를 조회한 마지막 시간 이후에 새로 올라온 공고만 조회할 수 있도록 해야 했다.
첫 번째 문제를 해결할 때 떠오른 고민은 다음과 같았다.
'지금은 모든 객체를 가져오는데 불필요한 데이터까지 전부 가져올 필요가 있나?'
'필요한 데이터만 데이터베이스에서 가져오는 방법이 있을 텐데.'
'아, 맞다. QueryDSL이 있었지!'
'QueryDSL을 사용하면 원하는 데이터를 DTO로 묶어서 한 번에 조회할 수 있겠다.'
'이렇게 일단 데이터베이스에서 조회하는 횟수를 한 번으로 줄이고.'
'그다음에는 반복문을 사용해서 데이터를 연결해 보자.'
우선 반환할 DTO를 비롯하여 이메일로 데이터를 전송하는 데 필요한 모든 레이어(layer)는 별도의 'notice' 패키지(package)에 모았다. 이렇게 분리해서 스케줄러 클래스의 로직이 바뀌더라도 기존 도메인(domain)에 영향을 주지 않도록 했다.
package com.project.cheerha.domain.notice.dto;
import com.querydsl.core.annotations.QueryProjection;
// [1/4] JobOpeningDto
public record JobOpeningDto(Long jobOpeningId, String url) {
@QueryProjection
public JobOpeningDto {
}
}package com.project.cheerha.domain.notice.dto;
import com.querydsl.core.annotations.QueryProjection;
// [2/4] JobOpeningKeywordDto
public record JobOpeningKeywordDto(Long jobOpeningId, Long keywordId) {
@QueryProjection
public JobOpeningKeywordDto {
}
}package com.project.cheerha.domain.notice.dto;
import com.querydsl.core.annotations.QueryProjection;
// [3/4] UserDto
public record UserDto(Long userId, String email) {
@QueryProjection
public UserDto {
}
}package com.project.cheerha.domain.notice.dto;
import com.querydsl.core.annotations.QueryProjection;
// [4/4] UserKeywordDto
public record UserKeywordDto(Long userId, Long keywordId) {
@QueryProjection
public UserKeywordDto {
}
}package com.project.cheerha.domain.notice.repository;
import com.project.cheerha.domain.notice.dto.JobOpeningDto;
import com.project.cheerha.domain.notice.dto.JobOpeningKeywordDto;
import com.project.cheerha.domain.notice.dto.UserDto;
import com.project.cheerha.domain.notice.dto.UserKeywordDto;
import java.util.List;
// [1/2] 데이터 조회를 담당하는 인터페이스 만들기
public interface NoticeCreationRepositoryQuery {
// 모든 사용자의 식별자 및 이메일 조회
List<UserDto> findAllUsers();
// 모든 채용 공고의 식별자 및 URL 조회
List<JobOpeningDto> findAllJobOpenings();
// 중간 테이블(JobOpeningKeyword) 조회
// 채용 공고의 식별자 및 키워드 식별자 목록 조회
List<JobOpeningKeywordDto> findAllJobOpeningKeywords();
// 중간 테이블(UserKeyword) 조회
// 사용자의 식별자 및 키워드 식별자 목록 조회
List<UserKeywordDto> findAllUserKeywords();
}package com.project.cheerha.domain.notice.repository;
import com.project.cheerha.domain.jobOpening.entity.QJobOpening;
import com.project.cheerha.domain.keyword.entity.QJobOpeningKeyword;
import com.project.cheerha.domain.keyword.entity.QUserKeyword;
import com.project.cheerha.domain.notice.dto.JobOpeningDto;
import com.project.cheerha.domain.notice.dto.JobOpeningKeywordDto;
import com.project.cheerha.domain.notice.dto.UserDto;
import com.project.cheerha.domain.notice.dto.UserKeywordDto;
import com.project.cheerha.domain.user.entity.QUser;
import com.querydsl.core.types.Projections;
import com.querydsl.jpa.impl.JPAQueryFactory;
import java.util.List;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Repository;
// [2/2] 인터페이스를 구현한 QueryDSL 기반 repository 만들기
@Repository
@RequiredArgsConstructor
public class NoticeCreationRepositoryQueryImpl implements NoticeCreationRepositoryQuery {
private final JPAQueryFactory queryFactory;
// 모든 채용 공고의 식별자 및 URL을 조회하는 메서드
@Override
public List<JobOpeningDto> findAllJobOpenings() {
QJobOpening jobOpening = QJobOpening.jobOpening;
return queryFactory
.select(Projections.constructor(
JobOpeningDto.class,
jobOpening.id,
jobOpening.jobOpeningUrl
)
).from(jobOpening)
.fetch();
}
// 모든 사용자의 식별자 및 이메일 조회
@Override
public List<UserDto> findAllUsers() {
QUser user = QUser.user;
return queryFactory
.select(Projections.constructor(
UserDto.class,
user.id,
user.email
)
).from(user)
.fetch();
}
// 중간 테이블(JobOpeningKeyword) 조회
// 채용 공고의 식별자 및 키워드 식별자 목록 조회
public List<JobOpeningKeywordDto> findAllJobOpeningKeywords() {
QJobOpeningKeyword jobOpeningKeyword = QJobOpeningKeyword.jobOpeningKeyword;
return queryFactory
.select(Projections.constructor(
JobOpeningKeywordDto.class,
jobOpeningKeyword.jobOpening.id,
jobOpeningKeyword.keyword.id
)
).from(jobOpeningKeyword)
.fetch();
}
// 중간 테이블(UserKeyword) 조회
// 사용자의 식별자 및 키워드 식별자 목록 조회
@Override
public List<UserKeywordDto> findAllUserKeywords() {
QUserKeyword userKeyword = QUserKeyword.userKeyword;
return queryFactory
.select(Projections.constructor(
UserKeywordDto.class,
userKeyword.user.id,
userKeyword.keyword.id
)
).from(userKeyword)
.fetch();
}
}package com.project.cheerha.domain.notice.service;
import com.project.cheerha.domain.notice.dto.JobOpeningDto;
import com.project.cheerha.domain.notice.dto.JobOpeningKeywordDto;
import com.project.cheerha.domain.notice.dto.UserDto;
import com.project.cheerha.domain.notice.dto.UserKeywordDto;
import com.project.cheerha.domain.notice.repository.NoticeCreationRepositoryQuery;
import java.util.List;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
@Service
@RequiredArgsConstructor
public class NoticeCreationService {
private final NoticeCreationRepositoryQuery repositoryQuery;
public List<UserDto> findAllUsers() {
return repositoryQuery.findAllUsers();
}
public List<JobOpeningDto> findAllJobOpenings() {
return repositoryQuery.findAllJobOpenings();
}
public List<JobOpeningKeywordDto> findAllJobOpeningKeywords() {
return repositoryQuery.findAllJobOpeningKeywords();
}
public List<UserKeywordDto> findAllUserKeywords() {
return repositoryQuery.findAllUserKeywords();
}
}package com.project.cheerha.domain.notice;
import com.project.cheerha.domain.notice.dto.JobOpeningDto;
import com.project.cheerha.domain.notice.dto.JobOpeningKeywordDto;
import com.project.cheerha.domain.notice.dto.UserDto;
import com.project.cheerha.domain.notice.dto.UserKeywordDto;
import com.project.cheerha.domain.notice.service.NoticeCreationService;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
@Slf4j
@Component
@RequiredArgsConstructor
public class NoticeCreationScheduler {
private final NoticeCreationService service;
@Scheduled(cron = "*/30 * * * * *")
@Transactional
public void sendJobOpeningMatchingNotices() {
List<JobOpeningKeywordDto> jobOpeningKeywordDtoList = service.findAllJobOpeningKeywords();
List<UserKeywordDto> userKeywordDtoList = service.findAllUserKeywords();
List<UserDto> userDtoList = service.findAllUsers();
List<JobOpeningDto> jobOpeningDtoList = service.findAllJobOpenings();
log.info("JobOpeningKeyword 목록: {}", jobOpeningKeywordDtoList);
log.info("UserKeyword 목록: {}", userKeywordDtoList);
log.info("사용자 목록: {}", userDtoList);
log.info("채용 공고 목록: {}", jobOpeningDtoList);
Map<Long, List<Long>> userKeywordMap = new HashMap<>();
for (UserKeywordDto dto : userKeywordDtoList) {
userKeywordMap.computeIfAbsent(
dto.userId(),
keywordId -> new ArrayList<>()
).add(dto.keywordId());
}
log.info("사용자별 키워드 목록: {}", userKeywordMap);
Map<Long, List<Long>> jobOpeningKeywordMap = new HashMap<>();
for (JobOpeningKeywordDto dto : jobOpeningKeywordDtoList) {
jobOpeningKeywordMap.computeIfAbsent(
dto.jobOpeningId(),
keywordId -> new ArrayList<>()
).add(dto.keywordId());
}
log.info("채용 공고별 키워드 목록: {}", jobOpeningKeywordMap);
Map<Long, List<Long>> matchingMap = new HashMap<>();
for (Map.Entry<Long, List<Long>> entry : userKeywordMap.entrySet()) {
Long userId = entry.getKey();
Set<Long> keywordIdSetChosenByUser = new HashSet<>(entry.getValue());
List<Long> jobOpeningIdList = jobOpeningKeywordMap.entrySet()
.stream()
.filter(jobOpening -> jobOpening.getValue()
.stream()
.anyMatch(keywordIdSetChosenByUser::contains)
).map(Map.Entry::getKey)
.toList();
if (!jobOpeningIdList.isEmpty()) {
matchingMap.put(userId, jobOpeningIdList);
log.info("{}번 사용자와 연결된 채용 공고: {}", userId, jobOpeningIdList);
}
}
}
}스케줄러를 뜯어고칠 때 처음 사용하는 메서드가 많아, 단계별로 쪼개서 주석을 달았다.
(1) 데이터베이스에서 필요한 데이터 가져오기 ▼
@Slf4j
@Component
@RequiredArgsConstructor
public class NoticeCreationScheduler {
private final NoticeCreationService service;
@Scheduled(cron = "*/30 * * * * *")
@Transactional
public void sendJobOpeningMatchingNotices() {
List<JobOpeningKeywordDto> jobOpeningKeywordDtoList = service.findAllJobOpeningKeywords();
List<UserKeywordDto> userKeywordDtoList = service.findAllUserKeywords();
List<UserDto> userDtoList = service.findAllUsers();
List<JobOpeningDto> jobOpeningDtoList = service.findAllJobOpenings();
log.info("JobOpeningKeyword 목록: {}", jobOpeningKeywordDtoList);
log.info("UserKeyword 목록: {}", userKeywordDtoList);
log.info("사용자 목록: {}", userDtoList);
log.info("채용 공고 목록: {}", jobOpeningDtoList);

코드를 수정한 뒤에는 로그 기록으로 쿼리문이 한 번씩만 나간다는 점을 확인할 수 있었다.
(2) userId를 키(key)로 사용하여 userKeywordMap에 매핑(mapping)하기 ▼
// key: userId (사용자 식별자)
// value: List<Long> (사용자가 고른 키워드의 식별자 목록)
// userKeywordMap: 사용자별로 선택한 키워드 ID 목록을 저장할 맵
Map<Long, List<Long>> userKeywordMap = new HashMap<>();
// - 사용자가 고른 keywordId 목록을 저장하는 List 생성
// - 해당 사용자가 고른 keywordId를 해당 List에 추가
for (UserKeywordDto dto : userKeywordDtoList) {
userKeywordMap.computeIfAbsent(
dto.userId(),
keywordId -> new ArrayList<>()
).add(dto.keywordId());
}
log.info("사용자별 키워드 목록: {}", userKeywordMap);(3) jobOpeningId를 키로 사용하여 jobOpeningKeywordMap에 매핑하기 ▼
// key: jobOpeningId (채용 공고 식별자)
// value: List<Long> (채용 공고에 포함된 키워드의 식별자 목록)
// jobOpeningKeywordMap: 채용 공고별로 포함된 키워드 ID 목록을 저장할 맵
Map<Long, List<Long>> jobOpeningKeywordMap = new HashMap<>();
// (1) 각 채용 공고에 포함된 keywordId 목록을 저장할 List 생성
// (2) 해당 채용 공고에 포함된 keywordId를 해당 List에 추가
for (JobOpeningKeywordDto dto : jobOpeningKeywordDtoList) {
jobOpeningKeywordMap.computeIfAbsent(
dto.jobOpeningId(),
keywordId -> new ArrayList<>()
).add(dto.keywordId());
}
log.info("채용 공고별 키워드 목록: {}", jobOpeningKeywordMap);(4) 사용자가 고른 키워드 목록을 확인하고, 각 키워드가 일치하는 채용 공고 찾기 ▼
// key: userId (사용자 식별자)
// value: List<Long> (사용자가 연결된 채용 공고의 식별자 목록)
// matchingMap: 사용자별로 매칭된 채용 공고 ID 목록을 저장할 맵
Map<Long, List<Long>> matchingMap = new HashMap<>();
// (1) 채용 공고 속 키워드 목록과 사용자가 고른 키워드 목록 비교
// (2) 키워드끼리 일치하는 채용 공고가 있으면 매핑
for (Map.Entry<Long, List<Long>> entry : userKeywordMap.entrySet()) {
Long userId = entry.getKey();
Set<Long> keywordIdSetChosenByUser = new HashSet<>(entry.getValue());
List<Long> jobOpeningIdList = jobOpeningKeywordMap.entrySet().stream()
.filter(jobOpening -> jobOpening.getValue().stream()
.anyMatch(keywordIdSetChosenByUser::contains))
// 사용자가 고른 키워드 목록에 해당 키워드가 있는지 확인
.map(Map.Entry::getKey)
// 키워드가 일치하는 채용 공고의 식별자 추출
.toList();
// 키워드가 일치하는 채용 공고 식별자를 사용자와 매핑
if (!jobOpeningIdList.isEmpty()) {
matchingMap.put(userId, jobOpeningIdList);
log.info("{}번 사용자와 연결된 채용 공고: {}", userId, jobOpeningIdList);
}
}
}
}(1) Map.Entry<Long, List<Long>> entry
- userKeywordMap에서 각 userId와 선택된 keywordId를 하나씩 가져오는 객체
(2) userKeywordMap.entrySet()
- userKeywordMap에 저장된 모든 항목을 Set 형태로 반환하는 메서드
- 항목: userId와 선택된 keywordId 목록을 포함하는 entry
(3) Long userId = entry.getKey();
- 사용자 식별자
(4) Set<Long> keywordIdSetChosenByUser = new HashSet<>(entry.getValue());
- 사용자가 고른 keywordId 목록을 Set으로 변환하여 중복 제거
(5) jobOpening.getValue();
- 채용 공고에 포함된 keywordId 목록
사용자가 고른 키워드가 포함된 채용 공고가 올바르게 연결되는지 로그로 확인한 다음에는, 이메일 전송 기능 구현과 조회한 채용 공고를 다시 조회하지 않도록 리팩토링(refactoring)하는 일정으로 넘어갔다.
Day 2에서 계속…….