[인용 및 참고 자료]
1. 구글 검색: 티스토리, "java.lang.Object org.hibernate.ScrollableResults.get(int)", 오류 해결하기, (2025.02.19)
2. 구글 검색: 티스토리, "java.lang.Object org.hibernate.ScrollableResults.get(int)", 오류 해결하기, (2025.02.19)
3. 구글 검색: QueryDSL GitHub, "java.lang.Object org.hibernate.ScrollableResults.get(int)", 오류 해결하기, (2025.02.19)
4. 구글 검색: 정책 브리핑, "한국 실업자 수", 2024년 12월 및 연간 고용동향, (2025.02.19)



package com.project.cheerha.domain.notice;
import com.project.cheerha.domain.notice.dto.JobOpeningKeywordDto;
import com.project.cheerha.domain.notice.dto.UserKeywordDto;
import com.project.cheerha.domain.notice.service.EmailFindService;
import com.project.cheerha.domain.notice.service.EmailService;
import java.time.Duration;
import java.time.Instant;
import java.time.ZoneId;
import java.time.ZonedDateTime;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
@Slf4j
@Component
@RequiredArgsConstructor
public class EmailSchedulerLv0 {
private final EmailFindService emailFindService;
private final EmailService emailService;
// 30초마다 채용 공고를 조회하여 이메일 전송
@Scheduled(cron = "*/30 * * * * *")
@Transactional
public void sendJobOpeningMatchingNotices() {
Instant startTime = Instant.now();
// 중복 조회를 방지하고자 조회 시간 사용
ZonedDateTime referenceTime = ZonedDateTime.now()
.minusDays(2L)
.withZoneSameInstant(ZoneId.of("UTC"));
Instant afterReferenceTime = Instant.now();
log.info("기준 시간 설정 완료 (소요 시간: {} ms)",
Duration.between(
startTime,
afterReferenceTime
).toMillis());
// 채용 공고의 ID 및 URL, 키워드 ID 조회
List<JobOpeningKeywordDto> jobOpeningKeywordDtoList = emailFindService.findAllJobOpeningKeywords(
referenceTime);
Instant afterJobKeywordFetch = Instant.now();
log.info("채용 공고 키워드 조회 완료 (소요 시간: {} ms)",
Duration.between(
afterReferenceTime,
afterJobKeywordFetch
).toMillis());
// 사용자의 ID 및 이메일, 키워드 ID 조회
List<UserKeywordDto> userKeywordDtoList = emailFindService.findAllUserKeywords();
Instant afterUserKeywordFetch = Instant.now();
log.info("사용자 키워드 조회 완료 (소요 시간: {} ms)",
Duration.between(
afterJobKeywordFetch,
afterUserKeywordFetch
).toMillis());
log.info("채용 공고 목록: {}", jobOpeningKeywordDtoList);
log.info("사용자 목록: {}", userKeywordDtoList);
// 사용자의 이메일 및 연결된 채용 공고 URL을 저장할 Map
Map<String, Set<String>> emailUrlMap = new HashMap<>();
// (1) 사용자 키워드 ID 목록 순회
for (UserKeywordDto userDto : userKeywordDtoList) {
// (2) 모든 채용 공고 키워드 ID 목록 순회
for (JobOpeningKeywordDto jobOpeningKeywordDto : jobOpeningKeywordDtoList) {
// (3) 키워드끼리 일치하는지 확인
boolean isUserKeywordMatchingJobKeyword = userDto.keywordId()
.equals(jobOpeningKeywordDto.keywordId());
// (4) 일치하면 이메일과 채용 공고 URL을 Map에 저장
if (isUserKeywordMatchingJobKeyword) {
emailUrlMap
.computeIfAbsent(
userDto.email(),
emailAsKey -> new HashSet<>()
).add(jobOpeningKeywordDto.url());
}
}
}
Instant afterMatching = Instant.now();
log.info("매칭 로직 수행 완료 (소요 시간: {} ms)",
Duration.between(
afterUserKeywordFetch,
afterMatching
).toMillis());
// (5) 이메일별로 알림 전송
emailUrlMap.forEach((email, urlSet) -> {
Instant emailStartTime = Instant.now();
log.info("사용자: {} - 매칭된 채용 공고: {}", email, urlSet);
emailService.sendMail(email, List.copyOf(urlSet));
Instant emailEndTime = Instant.now();
Duration emailDuration = Duration.between(
emailStartTime,
emailEndTime
);
log.info("개별 이메일 전송 완료: {} (소요 시간: {} s {} ms)",
email,
emailDuration.toSeconds(),
emailDuration.toMillisPart()
);
}
);
Instant afterEmailSend = Instant.now();
Duration emailSendDuration = Duration.between(
afterMatching,
afterEmailSend
);
Duration totalDuration = Duration.between(
startTime,
afterEmailSend
);
log.info("전체 이메일 전송 완료 (소요 시간: {} s {} ms)",
emailSendDuration.toSeconds(),
emailSendDuration.toMillisPart()
);
log.info("전체 작업 완료 (총 소요 시간: {} s {} ms)",
totalDuration.toSeconds(),
totalDuration.toMillisPart()
);
}
}
사용자 3명, 채용 공고 2개를 임의로 데이터베이스에 저장하고 스케줄러(Scheduler)를 총 세 번 돌렸다. 그다음 단계별로 걸린 시간을 정리하여 평균치를 구했다.

키워드가 같은 채용 공고와 사용자를 연결해주는 단계는 '0 ms'로 나와서 생략했다. 리팩토링(refactoring)하기 전에 이메일을 하나 보내는 데 평균 7.277초가 걸렸다.
'7초 × 2,000명 = 14,000초'
시간으로 환산하면 대략 3시간 53분이 걸렸다.
다시 말해 2,000명에게 이메일을 하나씩 보내주는 데 4시간은 잡아야 했다!
어쩐지 너무 느리다 싶더라니. 내가 한국인이어서가 아니라 이메일 하나 보내는 데 속 터질 뻔했다. 우선 이메일 전송 구간을 고치기 전에 현재 코드가 너무 복잡해 보여서 스케줄러 로직부터 리팩토링했다.
(1) 사용하지 않는 데이터 제외하기: 사용자 식별자는 쓰지 않으므로 제외함 ▼

(2) transform() 메서드 및 List 대신 Map 사용하기 ▼

(3) 중첩 for문 수정하기 ▼

이렇게 수정한 다음 애플리케이션(appliation)을 실행하면…….

오류가 뜬다.
'java.lang.Object org.hibernate.ScrollableResults.get(int)'다행히 코드를 잘못 써서 발생한 오류는 아니었다. 현재 Spring Boot 3.4.2를 사용하는데, '3.x' 버전과 QueryDSL을 함께 사용하면 이 오류가 발생했다. 오류를 검색하니 같은 문제를 겪은 사람이 정말 많았다. QueryDSL 버전을 구버전으로 바꾸기도 한 가지 해결책이긴 했으나, 그랬다가 코드에 무슨 영향을 끼칠지 몰라 설정 파일에 'JPQLTemplates.DEFAULT'를 추가했다.
package com.project.cheerha.common.config;
import com.querydsl.jpa.JPQLTemplates;
import com.querydsl.jpa.impl.JPAQueryFactory;
import jakarta.persistence.EntityManager;
import jakarta.persistence.PersistenceContext;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class QueryDslConfig {
@PersistenceContext
private EntityManager entityManager;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(JPQLTemplates.DEFAULT, entityManager);
}
}오류를 잡은 다음에는 하루 종일 삽질만 했다. 틈틈이 남긴 코드 조각이 아까워서 놔두었다.
(1) 1차 삽질 ▼
package com.project.cheerha.domain.notice.repository;
import java.time.ZonedDateTime;
import java.util.List;
import java.util.Map;
public interface EmailRepositoryQuery {
List<Long> findKeywordIdListForUser();
Map<Long, List<String>> findAllJobOpeningKeywords(ZonedDateTime referenceTime);
Map<Long, List<String>> findUserEmailsByKeywordIds(List<Long> keywordIds);
}package com.project.cheerha.domain.notice.repository;
import static com.querydsl.core.group.GroupBy.groupBy;
import static com.querydsl.core.group.GroupBy.list;
import com.project.cheerha.domain.jobOpening.entity.QJobOpening;
import com.project.cheerha.domain.keyword.entity.QJobOpeningKeyword;
import com.project.cheerha.domain.keyword.entity.QUserKeyword;
import com.project.cheerha.domain.user.entity.QUser;
import com.querydsl.jpa.impl.JPAQueryFactory;
import java.time.ZonedDateTime;
import java.util.List;
import java.util.Map;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Repository;
@Repository
@RequiredArgsConstructor
public class EmailRepositoryQueryImpl implements EmailRepositoryQuery {
private final JPAQueryFactory queryFactory;
@Override
public List<Long> findKeywordIdListForUser() {
QUserKeyword userKeyword = QUserKeyword.userKeyword;
return queryFactory
.select(userKeyword.keyword.id)
.from(userKeyword)
.distinct()
.fetch();
}
@Override
public Map<Long, List<String>> findAllJobOpeningKeywords(
ZonedDateTime referenceTime
) {
QJobOpeningKeyword jok = QJobOpeningKeyword.jobOpeningKeyword;
QJobOpening jobOpening = QJobOpening.jobOpening;
return queryFactory
.from(jok)
.join(jok.jobOpening, jobOpening)
.where(jobOpening.createdAt.after(referenceTime))
.transform(
groupBy(jok.keyword.id)
.as(list(jobOpening.jobOpeningUrl))
);
}
@Override
public Map<Long, List<String>> findUserEmailsByKeywordIds(List<Long> keywordIdList) {
QUserKeyword userKeyword = QUserKeyword.userKeyword;
QUser user = QUser.user;
return queryFactory
.from(userKeyword)
.join(userKeyword.user, user)
.where(userKeyword.keyword.id.in(keywordIdList))
.transform(
groupBy(userKeyword.keyword.id)
.as(list(user.email))
);
}
}package com.project.cheerha.domain.notice.service;
import com.project.cheerha.domain.notice.repository.EmailRepositoryQuery;
import java.time.ZonedDateTime;
import java.util.List;
import java.util.Map;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Component;
@Component
@RequiredArgsConstructor
public class EmailDataFetchService {
private final EmailRepositoryQuery repositoryQuery;
public Map<Long, List<String>> findJobOpeningKeywordMap(ZonedDateTime referenceTime) {
return repositoryQuery.findAllJobOpeningKeywords(referenceTime);
}
public List<Long> findUserKeywordIds() {
return repositoryQuery.findKeywordIdListForUser();
}
public Map<Long, List<String>> findUserEmailsByKeywordIds(List<Long> keywordIds) {
return repositoryQuery.findUserEmailsByKeywordIds(keywordIds);
}
}package com.project.cheerha.domain.notice.scheduler;
import com.project.cheerha.domain.notice.service.EmailDataFetchService;
import com.project.cheerha.domain.notice.service.EmailService;
import java.time.ZoneId;
import java.time.ZonedDateTime;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
@Slf4j
@Component
@RequiredArgsConstructor
public class EmailScheduler {
private final EmailDataFetchService fetchService;
private final EmailService emailService;
@Scheduled(cron = "*/30 * * * * *")
@Transactional
public void sendJobOpeningMatchingNotices() {
ZonedDateTime referenceTime = ZonedDateTime.now()
.minusDays(3L)
.withZoneSameInstant(ZoneId.of("UTC"));
Map<Long, List<String>> jobOpeningKeywordMap = fetchService
.findJobOpeningKeywordMap(referenceTime);
List<Long> userKeywordIdList = fetchService.findUserKeywordIds();
Map<String, Set<String>> emailUrlMap = new HashMap<>();
for (Long keywordId : userKeywordIdList) {
List<String> matchingUrlList = jobOpeningKeywordMap
.getOrDefault(keywordId, List.of());
if (!matchingUrlList.isEmpty()) {
Map<Long, List<String>> keywordIdEmailMap = fetchService
.findUserEmailsByKeywordIds(List.of(keywordId));
List<String> emailList = keywordIdEmailMap.get(keywordId);
emailList.forEach(email -> emailUrlMap
.computeIfAbsent(
email,
emailAsKey -> new HashSet<>())
.addAll(matchingUrlList));
}
}
emailUrlMap.forEach(
(email, urlSet) -> {
log.info("매칭 결과: {} - {}", email, urlSet);
emailService.sendMail(email, List.copyOf(urlSet));
});
}
}(2) 2차 삽질 ▼
package com.project.cheerha.domain.notice.repository;
import java.time.ZonedDateTime;
import java.util.List;
import java.util.Map;
public interface EmailRepositoryQuery {
Map<Long, List<String>> findAllJobOpeningKeywords(ZonedDateTime referenceTime);
Map<Long, List<String>> findAllUserKeywords();
}package com.project.cheerha.domain.notice.repository;
import static com.querydsl.core.group.GroupBy.groupBy;
import static com.querydsl.core.group.GroupBy.list;
import com.project.cheerha.domain.jobOpening.entity.QJobOpening;
import com.project.cheerha.domain.keyword.entity.QJobOpeningKeyword;
import com.project.cheerha.domain.keyword.entity.QUserKeyword;
import com.project.cheerha.domain.user.entity.QUser;
import com.querydsl.jpa.impl.JPAQueryFactory;
import java.time.ZonedDateTime;
import java.util.List;
import java.util.Map;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Repository;
@Repository
@RequiredArgsConstructor
public class EmailRepositoryQueryImpl implements EmailRepositoryQuery {
private final JPAQueryFactory queryFactory;
@Override
public Map<Long, List<String>> findAllJobOpeningKeywords(
ZonedDateTime referenceTime
) {
QJobOpeningKeyword jok = QJobOpeningKeyword.jobOpeningKeyword;
QJobOpening jobOpening = QJobOpening.jobOpening;
return queryFactory
.from(jok)
.join(jok.jobOpening, jobOpening)
.where(jobOpening.createdAt.after(referenceTime))
.transform(
groupBy(jok.keyword.id)
.as(list(jobOpening.jobOpeningUrl))
);
}
@Override
public Map<Long, List<String>> findAllUserKeywords() {
QUserKeyword userKeyword = QUserKeyword.userKeyword;
QUser user = QUser.user;
return queryFactory
.from(userKeyword)
.join(userKeyword.user, user)
.transform(
groupBy(userKeyword.keyword.id)
.as(list(user.email))
);
}
}package com.project.cheerha.domain.notice.service;
import com.project.cheerha.domain.notice.repository.EmailRepositoryQuery;
import java.time.ZonedDateTime;
import java.util.List;
import java.util.Map;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Component;
@Component
@RequiredArgsConstructor
public class EmailDataFetchService {
private final EmailRepositoryQuery repositoryQuery;
public Map<Long, List<String>> findJobOpeningKeywordMap(ZonedDateTime referenceTime) {
return repositoryQuery.findAllJobOpeningKeywords(referenceTime);
}
public Map<Long, List<String>> findUserKeywordMap() {
return repositoryQuery.findAllUserKeywords();
}
}package com.project.cheerha.domain.notice.scheduler;
import com.project.cheerha.domain.notice.service.EmailDataFetchService;
import com.project.cheerha.domain.notice.service.EmailService;
import java.time.ZoneId;
import java.time.ZonedDateTime;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
@Slf4j
@Component
@RequiredArgsConstructor
public class EmailScheduler {
private final EmailDataFetchService fetchService;
private final EmailService emailService;
@Scheduled(cron = "*/30 * * * * *")
@Transactional
public void sendJobOpeningMatchingNotices() {
ZonedDateTime referenceTime = ZonedDateTime.now()
.minusDays(3L)
.withZoneSameInstant(ZoneId.of("UTC"));
Map<Long, List<String>> jobOpeningKeywordMap = fetchService
.findJobOpeningKeywordMap(referenceTime);
Map<Long, List<String>> userKeywordMap = fetchService
.findUserKeywordMap();
Map<String, Set<String>> emailUrlMap = new HashMap<>();
userKeywordMap.forEach((keywordId, emailList) -> {
List<String> matchingUrlList = jobOpeningKeywordMap
.getOrDefault(keywordId, List.of());
if (!matchingUrlList.isEmpty()) {
emailList.forEach(email -> emailUrlMap
.computeIfAbsent(
email,
key -> new HashSet<>())
.addAll(matchingUrlList)
);
}
});
emailUrlMap.forEach((email, urlSet) -> {
log.info("매칭 결과: {} - {}", email, urlSet);
emailService.sendMail(email, List.copyOf(urlSet));
});
}
}
현재 각 스레드(thread)가 사용자 한 명을 맡았는데, 스레드 풀(thread pool)을 설정하여 여러 스레드를 사용하여 작업 속도를 높이기로 했다. 지금은 사용자 2,000명에게 이메일을 보내는 데 약 4시간이 걸리지만, 만약 스레드 10개를 사용한다면, '240 ÷ 10 = 24'로 24분 내외로 작업이 끝났다.
팀에서는 이메일을 지나치게 자주 보내면 사용자들이 불편할 수 있다고 생각하여 12시간 간격으로 하루에 두 번 보낼 예정이었다. 이번에는 아침 8시에 한 번, 저녁 7시에 한 번 보낸다고 가정하고 최대 몇 명에게 이메일을 보낼 수 있는지 계산했다.
ⓐ 24분에 사용자 2,000명에게 전송 가능
ⓑ 아침 8시부터 저녁 7시까지는 11시간, 즉 660분 여유가 있음
ⓒ 한 작업에 24분 걸리므로, 660분 ÷ 24분 = 약 27.5번 작업 가능
ⓓ 횟수를 27로 잡고 계산하면 27번 작업 × 2,000명 = 54,000명에게 이메일 전송 가능
ⓔ 저녁 7시부터 아침 8시까지는 13시간, 즉 780분 여유가 있음
ⓕ 780분 ÷ 24분 = 32.5분 ⭢ 32번 작업 × 2,000명 = 64,000명에게 이메일 전송 가능
ⓖ 하루에 총 54,000명 + 64,000명 = 118,000명에게 이메일 전송 가능
기존에는 (24시간 ÷ 4시간)X2,000명 = 12,000명에게 보냈다면, 스레드 풀을 설정했을 때에는 아래와 같은 수치가 나왔다.
118,000÷12,000=9.8333…….
즉. 스레드 풀을 설정해서 여러 스레드를 사용한다면 약 9.83배 더 많은 사용자에게 맞춤 채용 공고 이메일을 보낼 수 있었다.
이제 작업 속도를 높일 방법도 떠올렸겠다, 스레드 풀부터 얼른 설정했다.
(1) 스레드 풀(Thread Pool) 생성하기 ▼
package com.project.cheerha.common.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;
@Configuration
public class SchedulerConfig {
// 이메일 전송 스케줄러에 맞는 스레드 풀 생성
@Bean
public ThreadPoolTaskScheduler emailTaskScheduler() {
ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();
// 스레드 풀의 크기 설정
scheduler.setPoolSize(10);
// 스레드 이름 접두사를 설정하여 스레드 구분
// 특수 기호를 사용해서 검색 시 쉽게 찾도록 함
scheduler.setThreadNamePrefix("$$$-Email-Scheduler-thread-");
// 설정이 끝난 스케줄러 반환
return scheduler;
}
}이때 이름을 잘못 지으면 빈(Bean)끼리 충돌하는 문제가 생기므로 주의해야 한다.
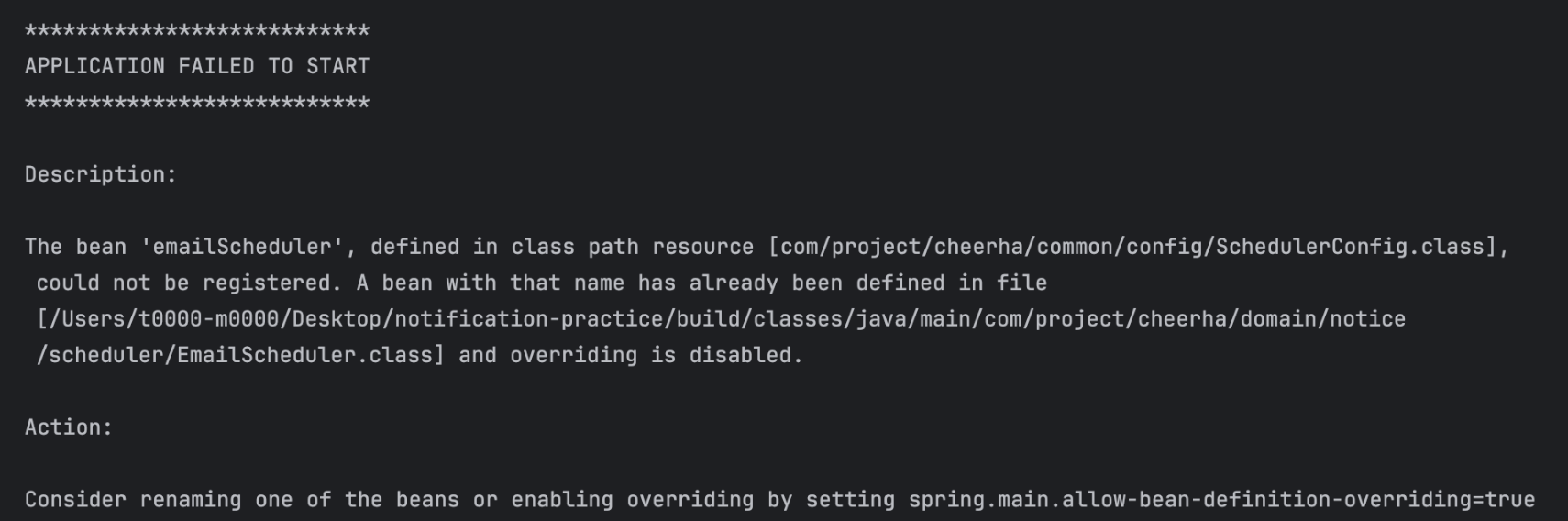
The bean 'emailScheduler', defined in class path resource
[com/project/cheerha/common/config/SchedulerConfig.class],
could not be registered.
A bean with that name has already been defined in file
and overriding is disabled.
- emailScheduler라는 빈이 두 번 정의되어 발생한 오류
(1) SchedulerConfig에서 정의된 빈(bean)
(2) EmailScheduler에 이미 @Component로 등록된 빈
- Spring은 빈 이름이 중복되면 오류를 발생시킴(2) 이메일 스케줄러(Email Scheduler)에 반영하기 ▼
package com.project.cheerha.domain.notice.scheduler;
import com.project.cheerha.domain.notice.UserDto;
import com.project.cheerha.domain.notice.service.EmailDataFetchService;
import com.project.cheerha.domain.notice.service.EmailService;
import java.time.Duration;
import java.time.Instant;
import java.time.ZoneId;
import java.time.ZonedDateTime;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.CompletableFuture;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
@Slf4j
@Component
@RequiredArgsConstructor
public class EmailScheduler {
private final EmailDataFetchService fetchService;
private final EmailService emailService;
private final ThreadPoolTaskScheduler threadPoolScheduler;
@Scheduled(cron = "*/30 * * * * *")
@Transactional
public void sendJobOpeningMatchingNotices() {
Instant start = Instant.now();
ZonedDateTime referenceTime = ZonedDateTime.now()
.minusDays(3L)
.withZoneSameInstant(ZoneId.of("UTC"));
Instant referenceTimeSetEnd = Instant.now();
log.info("기준 시간 설정 완료 (소요 시간: {} ms)", Duration.between(start, referenceTimeSetEnd).toMillis());
Instant jobOpeningKeywordStart = Instant.now();
Map<Long, List<String>> jobOpeningKeywordMap = fetchService.findJobOpeningKeywordMap(referenceTime);
Instant jobOpeningKeywordEnd = Instant.now();
log.info("채용 공고 키워드 조회 완료 (소요 시간: {} ms)", Duration.between(jobOpeningKeywordStart, jobOpeningKeywordEnd).toMillis());
Instant userKeywordStart = Instant.now();
List<UserDto> userDtoList = fetchService.findUserKeywordList();
Instant userKeywordEnd = Instant.now();
log.info("사용자 키워드 조회 완료 (소요 시간: {} ms)", Duration.between(userKeywordStart, userKeywordEnd).toMillis());
Instant matchingLogicStart = Instant.now();
Map<String, Set<String>> emailUrlMap = new HashMap<>();
for (UserDto dto : userDtoList) {
List<String> matchingUrlList = jobOpeningKeywordMap.getOrDefault(
dto.keywordId(),
List.of()
);
if (!matchingUrlList.isEmpty()) {
emailUrlMap.computeIfAbsent(
dto.email(),
email -> new HashSet<>()
).addAll(matchingUrlList);
}
}
Instant matchingLogicEnd = Instant.now();
log.info("매칭 로직 수행 완료 (소요 시간: {} ms)", Duration.between(matchingLogicStart, matchingLogicEnd).toMillis());
Instant emailSendingStart = Instant.now();
List<CompletableFuture<Void>> futures = new ArrayList<>();
emailUrlMap.forEach((email, urlSet) -> {
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
log.info("사용자: {} - 매칭된 채용 공고: {}", email, urlSet);
Instant sendStart = Instant.now();
emailService.sendMail(email, urlSet);
Instant sendEnd = Instant.now();
log.info("개별 이메일 전송 완료: {} (소요 시간: {}s {}ms)", email, Duration.between(sendStart, sendEnd).getSeconds(), Duration.between(sendStart, sendEnd).toMillis() % 1000);
}, threadPoolScheduler);
futures.add(future);
});
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
Instant emailSendingEnd = Instant.now();
log.info("전체 이메일 전송 완료 (소요 시간: {}s {}ms)",
Duration.between(emailSendingStart, emailSendingEnd).getSeconds(),
Duration.between(emailSendingStart, emailSendingEnd).toMillis() % 1000);
Instant end = Instant.now();
log.info("전체 작업 완료 (총 소요 시간: {}s {}ms)", Duration.between(start, end).getSeconds(), Duration.between(start, end).toMillis() % 1000);
}
}
리팩토링 뒤에 다시 스케줄러를 세 번 돌려서 결과를 확인했다.

로그 기록이 뜨는 모양새를 보면서 스레드 풀 설정 전후 차이를 더욱 확실히 느꼈다. 개별 이메일 전송 완료가 거의 동시에 출력되었고, 전체 이메일 전송에 걸린 시간이 개별 이메일 전송의 총합이 아니었다. 이메일을 보내는 데 걸리는 시간 자체를 줄이지 못한 점은 아쉬웠으나, 전체 작업 속도를 줄여서 뿌듯했다. 수치로 얼마나 개선되었는지 확인하고 정리하는 시간이 기능이 동작할 때만큼이나 즐거웠다.

스케줄러(Scheduler)를 고치면서 세 가지 사항이 바뀌었다.
(1) QueryDSL의 transform() 메서드 사용 [깃허브 링크]

(2) Q클래스를 선언하지 않고 static import하여 사용 [깃허브 링크]


(3) Projections 대신 생성자 사용 [깃허브 링크]
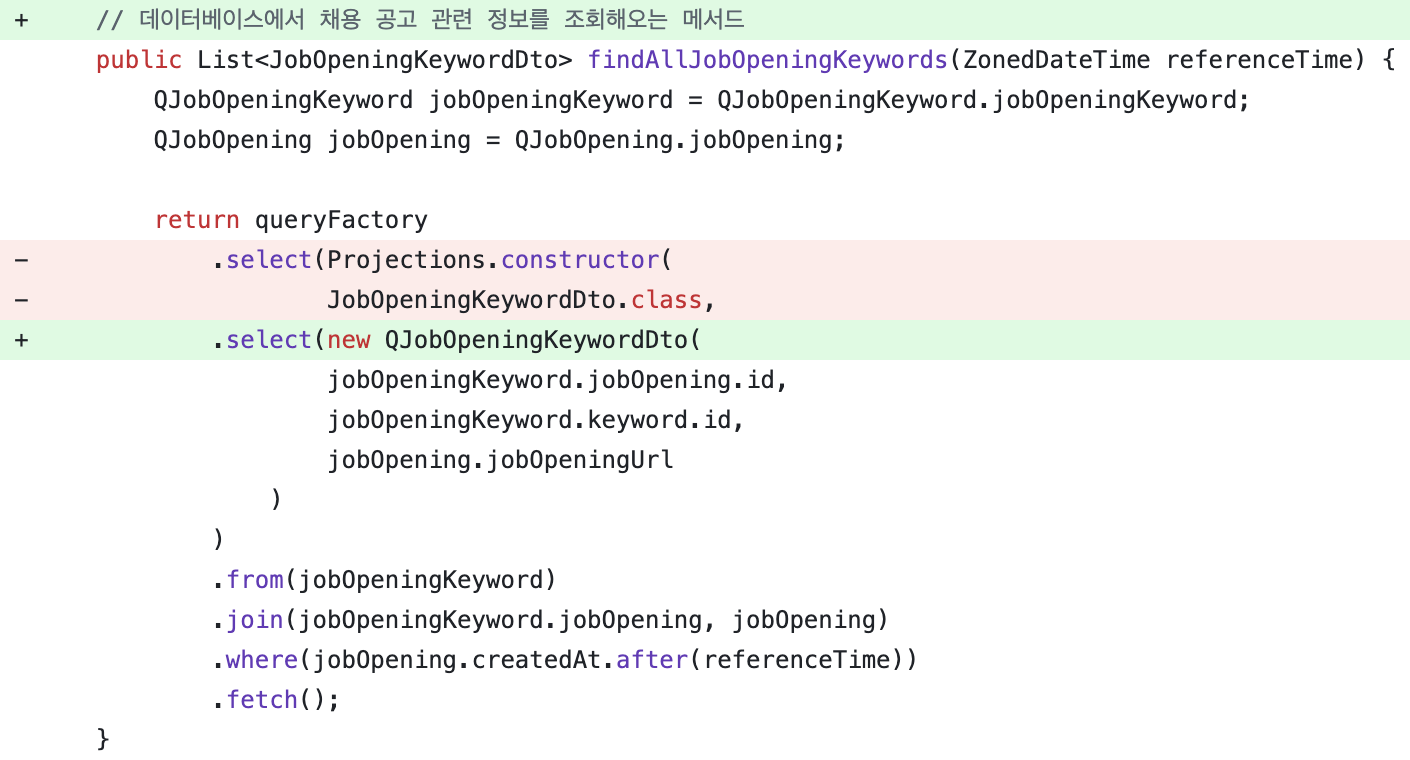
이렇게 속도 향상이 얼추 마무리되는가 싶었는데…….
"스레드 풀(Thread Pool)을 꼭 명시해야 할까요? 스프링(Spring)이 알아서 관리하도록 놔둬도 되지 않을까요?"
Day 6에서 계속…….