1. 프로젝트 진행 상황 및 계획
🥇 이메일 전송 기능 구현 전 필요한 로직(logic) 정리하기 (진행 중, 2025.02.15 완료 목표)
🥈 스프링 스케줄러(Spring Scheduler)로 이메일 전송 기능 구현하기 (진행 중, 2025.02.16 완료 목표)
🥉 실시간 알림 기능 구현 방법 및 각 방법의 장단점 공부하기 (진행 중, 2025.02.23 완료 목표)
4️⃣ API 명세서 수정 및 검토하기 (진행 전, 2025.02.23 완료 목표)
5️⃣ 리드미(README) 틀 완성하기 (진행 전, 2025.02.23 완료 목표)
6️⃣ MVP(최소 기능 제품) 버전 테스트 코드 작성하기 (진행 전, 2025.02.23 완료 목표)
2. CSV 파일이 없어서 만들어서 썼다.
(1) 채용 공고: 10,000개
(2) 기술 키워드: 45개
(3) 기술 키워드는 채용 공고당 5개에서 10개씩 포함되도록 설정 필요
(4) 사용자: 2,000명
프로젝트 진행 기간에 쓸 더미 데이터(dummy data)가 필요해서 챗GPT에 거듭 부탁하다가 문득, 의구심이 들었다.
'마음에 드는 더미 데이터가 나올 때까지 챗GPT를 닦달하느니, 차라리 생성용 코드를 직접 짜는 편이 훨씬 낫겠다.'
package com.project.cheerha.common.generator;
import java.io.FileWriter;
import java.io.IOException;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class KeywordGenerator {
public static void main(String[] args) {
// 데이터 생성에 사용할 기술 키워드 배열
String[] technologies = {
"Java", "Kafka", "Elasticsearch", "Spring Boot", "React",
"Angular", "Vue.js", "Node.js", "Python", "Django",
"Flask", "Ruby on Rails", "Go", "Kubernetes", "Docker",
"AWS", "Azure", "Firebase", "Terraform", "MySQL",
"PostgreSQL", "MongoDB", "Redis", "Cassandra", "Oracle DB",
"SQLite", "Apache Solr", "Hadoop", "Spark", "Apache Camel",
"Apache NiFi", "Jenkins", "Git", "GitHub", "GitLab",
"Bitbucket", "CI/CD", "JUnit", "TestNG", "Mockito",
"Swagger", "GraphQL", "REST API", "OAuth", "JWT"
};
try (FileWriter writer = new FileWriter("keywords.csv")) {
// CSV 헤더 작성
writer.append("id,name\n");
// 키워드 수만큼 데이터 생성
for (int i = 0; i < technologies.length; i++) {
// id는 1부터 시작
int id = i + 1;
String technology = technologies[i];
// CSV 파일에 기록
writer.append(String.valueOf(id)).append(",")
.append(technology).append("\n");
}
log.info("CSV 파일 생성 성공");
} catch (IOException e) {
log.error("파일 생성 중 오류 발생: {}", String.valueOf(e));
}
}
}package com.project.cheerha.common.generator;
import com.project.cheerha.common.properties.BcryptSecurityProperties;
import com.project.cheerha.common.util.PasswordEncoder;
import com.project.cheerha.domain.user.entity.User.Role;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Random;
import java.util.Set;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class UserGenerator {
public static void main(String[] args) {
int userCount = 2000; // 사용자 수
int maxSameNameCount = 3; // 허용하는 최대 동명이인 수
Random random = new Random();
// 사용자 이름을 생성할 때 사용할 성(姓) 배열
String[] familyNames = {
"김", "이", "박", "최", "정",
"강", "조", "윤", "장", "임",
"신", "문", "한", "오", "주"
};
// 사용자 이름을 생성할 때 사용할 이름 배열
String[] givenNames = {
"은비", "수호", "한비", "지민", "서연", "민아", "수아", "진우", "상엽", "유진",
"지우", "하늘", "소윤", "지아", "예린", "하린", "태연", "유나", "선우", "은채",
"주희", "민정", "연우", "태영", "서빈", "정민", "연수", "주현", "지후", "하영",
"예슬", "지원", "나래", "서경", "다혜", "세영", "미래", "지효", "수연", "유림",
"정희", "나은", "소연", "연정", "하연", "다솜", "미경", "정하", "정미", "효정",
"수빈", "지유", "영지", "나영", "소영", "진아", "희정", "윤경", "유선", "정연",
"미린", "은서", "세은", "주하", "소림", "채원", "지수", "선미", "정화", "세라"
};
// 이메일 고유 값 생성
// 예시) user1@gmail.com, user2@gmail.com ...
Set<String> uniqueEmails = new HashSet<>();
// 이름별 출현 횟수
Map<String, Integer> nameCounts = new HashMap<>();
// BcryptSecurityProperties 객체 수동 생성
// 예시: bcrypt의 cost 값 직접 설정
BcryptSecurityProperties bcryptProperties = new BcryptSecurityProperties();
BcryptSecurityProperties.Bcrypt bcryptConfig = new BcryptSecurityProperties.Bcrypt();
bcryptConfig.setCost(4);
// cost 값 예시
// 비밀번호 암호화 시 연산의 복잡도를 4로 설정
bcryptProperties.setBcrypt(bcryptConfig);
// PasswordEncoder 사용
PasswordEncoder passwordEncoder = new PasswordEncoder(bcryptProperties);
try (FileWriter writer = new FileWriter("users.csv")) {
// 헤더 작성
writer.append("id,career,email,name,password,role,age\n");
// 사용자 수만큼 데이터 생성
for (int userId = 1; userId <= userCount; userId++) {
// 직업 경력은 0(없음)에서 9 사이 무작위로 선택
// 0~3년 경력이 70% 비율이 되도록 설정
int career = random.nextInt(100) < 70 ? random.nextInt(4) : 4 + random.nextInt(6);
// 이메일 고유 값 처리
String email = "user" + userId + "@gmail.com";
while (uniqueEmails.contains(email)) {
email = "user" + random.nextInt(userCount) + "@gmail.com";
// 중복 이메일 피하기
}
uniqueEmails.add(email);
// 이름 생성
String familyName = familyNames[random.nextInt(familyNames.length)];
String givenName = givenNames[random.nextInt(givenNames.length)];
String name = familyName + givenName;
// 이름 중복 확인
int nameCount = nameCounts.getOrDefault(name, 0);
if (nameCount < maxSameNameCount) {
// 동명이인이 허용 범위 내이면 사용
nameCounts.put(name, nameCount + 1);
} else {
// 동명이인 초과 시 다른 이름 생성
while (nameCounts.getOrDefault(name, 0) >= maxSameNameCount) {
familyName = familyNames[random.nextInt(familyNames.length)];
givenName = givenNames[random.nextInt(givenNames.length)];
name = familyName + givenName;
}
nameCounts.put(name, 1);
// 새로운 이름은 1로 설정
}
// 비밀번호 설정 후 암호화
String rawPassword = "password123";
String hashedPassword = passwordEncoder.encode(rawPassword);
// role은 "USER"로 enum 반영
String role = Role.USER.name();
// 나이 설정
// 100을 기준으로 비율 조정
int age;
int ageGroup = random.nextInt(100);
if (ageGroup < 70) {
// 70%는 19~20대
age = 19 + random.nextInt(12); // 19~30대
} else if (ageGroup < 90) {
// 20%는 30대
age = 30 + random.nextInt(11); // 30~39세
} else {
// 10%는 40대 이상
age = 40 + random.nextInt(21); // 40~59세
}
// CSV 파일에 기록
writer.append(String.valueOf(userId)).append(",")
.append(String.valueOf(career)).append(",")
.append(email).append(",")
.append(name).append(",")
.append(hashedPassword).append(",")
.append(role).append(",")
.append(String.valueOf(age)).append("\n");
}
log.info("CSV 파일 생성 성공");
} catch (IOException e) {
log.error("파일 생성 중 오류 발생: {}", String.valueOf(e));
}
}
}package com.project.cheerha.common.generator;
import com.project.cheerha.common.properties.BcryptSecurityProperties;
import com.project.cheerha.common.util.PasswordEncoder;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Random;
import java.util.Set;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class UserGeneratorWithoutAge {
public static void main(String[] args) {
int userCount = 2000; // 사용자 수
int maxSameNameCount = 3; // 허용하는 최대 동명이인 수
Random random = new Random();
// 사용자 이름을 생성할 때 사용할 성(姓) 배열
String[] familyNames = {
"김", "이", "박", "최", "정",
"강", "조", "윤", "장", "임",
"신", "문", "한", "오", "주"
};
// 사용자 이름을 생성할 때 사용할 이름 배열
String[] givenNames = {
"은비", "수호", "한비", "지민", "서연", "민아", "수아", "진우", "상엽", "유진",
"지우", "하늘", "소윤", "지아", "예린", "하린", "태연", "유나", "선우", "은채",
"주희", "민정", "연우", "태영", "서빈", "정민", "연수", "주현", "지후", "하영",
"예슬", "지원", "나래", "서경", "다혜", "세영", "미래", "지효", "수연", "유림",
"정희", "나은", "소연", "연정", "하연", "다솜", "미경", "정하", "정미", "효정",
"수빈", "지유", "영지", "나영", "소영", "진아", "희정", "윤경", "유선", "정연",
"미린", "은서", "세은", "주하", "소림", "채원", "지수", "선미", "정화", "세라"
};
// 이메일 고유값 생성
Set<String> uniqueEmails = new HashSet<>();
// 이름별 출현 횟수
Map<String, Integer> nameCounts = new HashMap<>();
// BcryptSecurityProperties 객체 수동 생성
BcryptSecurityProperties bcryptProperties = new BcryptSecurityProperties();
BcryptSecurityProperties.Bcrypt bcryptConfig = new BcryptSecurityProperties.Bcrypt();
bcryptConfig.setCost(4);
// cost 값 예시
// 비밀번호 암호화 시 연산의 복잡도를 4로 설정
bcryptProperties.setBcrypt(bcryptConfig);
// PasswordEncoder 사용
PasswordEncoder passwordEncoder = new PasswordEncoder(bcryptProperties);
try (FileWriter writer = new FileWriter("users_without_age.csv")) {
// 헤더 작성
writer.append("id,career,email,name,password,role\n");
// 사용자 수만큼 데이터 생성
for (int userId = 1; userId <= userCount; userId++) {
// 직업 경력은 0(없음)에서 9 사이 무작위로 선택
// 0~3년 경력이 70% 비율이 되도록 설정
int career = random.nextInt(100) < 70 ? random.nextInt(4) : 4 + random.nextInt(6);
// 이메일 고유 값 처리
String email = "user" + userId + "@gmail.com";
while (uniqueEmails.contains(email)) {
email = "user" + random.nextInt(userCount) + "@gmail.com";
// 중복 이메일 피하기
}
uniqueEmails.add(email);
// 이름 생성
String familyName = familyNames[random.nextInt(familyNames.length)];
String givenName = givenNames[random.nextInt(givenNames.length)];
String name = familyName + givenName;
// 이름 중복 확인
int nameCount = nameCounts.getOrDefault(name, 0);
if (nameCount < maxSameNameCount) {
nameCounts.put(name, nameCount + 1);
} else {
while (nameCounts.getOrDefault(name, 0) >= maxSameNameCount) {
familyName = familyNames[random.nextInt(familyNames.length)];
givenName = givenNames[random.nextInt(givenNames.length)];
name = familyName + givenName;
}
nameCounts.put(name, 1);
// 새 이름은 1로 설정
}
// 비밀번호 설정 후 암호화
String rawPassword = "password123";
String hashedPassword = passwordEncoder.encode(rawPassword);
// role은 항상 '0'으로 설정
int role = 0;
// CSV 파일에 기록
writer.append(String.valueOf(userId)).append(",")
.append(String.valueOf(career)).append(",")
.append(email).append(",")
.append(name).append(",")
.append(hashedPassword).append(",")
.append(String.valueOf(role)).append("\n");
}
log.info("CSV 파일 생성 성공");
} catch (IOException e) {
log.error("파일 생성 중 오류 발생: {}", String.valueOf(e));
}
}
}package com.project.cheerha.common.generator;
import java.io.FileWriter;
import java.io.IOException;
import java.time.ZoneId;
import java.time.ZonedDateTime;
import java.util.Random;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class JobOpeningGenerator {
public static void main(String[] args) {
int jobOpeningCount = 10000; // 생성할 채용 공고 수
Random random = new Random();
// Random 객체로 무작위 값 생성
// 데이터 생성에 사용할 회사명 배열
String[] companies = {
"삼성", "LG", "카카오", "네이버", "구글", "마이크로소프트", "애플", "토스", "배달의민족", "카페24",
"당근마켓", "마켓컬리", "롯데", "SK", "한화", "KT", "현대자동차", "포스코", "삼성전자", "LG전자",
"CJ", "쿠팡", "위메프", "11번가", "인터파크", "다이소", "이마트", "삼성생명", "교보문고", "하이닉스",
"제일기획", "넥슨", "넷마블", "엔씨소프트", "반도건설", "현대백화점", "신세계", "롯데쇼핑", "삼성SDS", "카카오게임즈",
"배달통", "레진코믹스", "마켓플러스", "왓챠", "피지컬갤러리", "브랜디", "오르비", "부릉", "그라운드X", "라인플러스",
"모두의연애", "윙크", "아모레퍼시픽", "셀트리온", "비바리퍼블리카", "아이디병원", "피자헛", "도미노피자", "올리브영",
"브라운백", "삼성물산", "SK텔레콤", "농심", "기아", "삼성전기", "LG디스플레이", "아시아나항공", "대한항공", "롯데면세점",
"유한양행", "한미약품", "광주은행", "하나금융그룹", "신한은행", "삼성카드", "현대카드", "롯데카드", "BC카드", "KB국민카드",
"우리은행", "카카오뱅크", "토스뱅크", "NH농협은행", "하나은행", "삼성생명", "AIG손해보험", "한화생명", "메리츠화재", "롯데손해보험",
"셀트리온헬스케어", "헬로윤미", "코스모스", "메타넷", "LG화학", "신세계인터내셔날", "LG생활건강", "애경", "유니레버", "한국타이어",
"두산", "넥스트레벨", "뷰웍스", "영림원소프트랩", "모비스", "컴투스", "게임빌", "게임펍", "카트라이더", "타이탄", "쿠팡플러스",
"에어비앤비", "우버", "배달의민족", "링크드인", "패스트파이브", "티몬", "오늘의집", "필립스", "시그마", "하이네켄", "애드테크",
"알리바바", "아이유브이", "로젠택배", "네오위즈", "스마일게이트", "리틀빅아이디어", "넥스트챌린지", "더존비즈온", "로켓펀치"
};
// 데이터 생성에 사용할 학력 수준 배열
String[] educationLevels = {"고졸", "대졸", "석사", "박사", "무관"};
// 데이터 생성에 사용할 고용 형태 배열
String[] employmentTypes = {"정규직", "계약직", "프리랜서", "아르바이트"};
// 데이터 생성에 사용할 지역 배열
String[] locations = {
"서울", "부산", "대전", "대구", "광주",
"인천", "수원", "울산", "창원", "청주"
};
// 데이터 생성에 사용할 직무 배열
String[] positions = {
"백엔드 개발자", "Java 개발자", "Spring 개발자", "Node.js 개발자", "풀스택",
"데이터베이스 관리자(DBA)", "시스템 엔지니어", "데브옵스 엔지니어", "클라우드 엔지니어", "데이터 엔지니어",
"웹 애플리케이션 개발자", "프론트엔드 개발자", "파이썬 개발자", "자바스크립트 개발자", "QA"
};
try (FileWriter writer = new FileWriter("job_openings.csv")) {
// CSV 헤더 작성
writer.append(
"id,company,education_level,employment_type,hiring_end_at,hiring_start_at,job_opening_url,location,max_experience_years,min_experience_years,salary,title,view_count,position\n");
// 지정된 채용 공고 수만큼 값 생성
for (int jobOpeningId = 1; jobOpeningId <= jobOpeningCount; jobOpeningId++) {
// 무작위로 값 생성
String company = companies[random.nextInt(companies.length)];
String educationLevel = educationLevels[random.nextInt(educationLevels.length)];
String location = locations[random.nextInt(locations.length)];
String position = positions[random.nextInt(positions.length)];
// 고용 형태의 50%는 정규직, 나머지는 무작위
String employmentType = "정규직";
if (random.nextDouble() > 0.5) {
int randomType = random.nextInt(3);
employmentType = employmentTypes[randomType + 1];
}
// 채용 시작일을 현재 날짜로 설정
ZonedDateTime now = ZonedDateTime.now(ZoneId.of("Asia/Seoul"));
String hiringStartAt = now.toString();
// 채용 기간을 7일에서 30일 사이 무작위로 설정
int duration = 7 + random.nextInt(24);
ZonedDateTime hiringEndAt = now.plusDays(duration);
String hiringEndAtStr = hiringEndAt.toString();
// 고유한 채용 공고 URL 생성
String jobOpeningUrl = "https://example.com/job/" + jobOpeningId;
// 최소 연차 및 최대 연차 무작위 생성
// maxExperienceYears: 1~5년
// minExperienceYears: 0~2년
int maxExperienceYears = 1 + random.nextInt(5);
int minExperienceYears = random.nextInt(3);
// 3000만에서 5000만 사이로 연봉 무작위 생성
int salary = 30000000 + random.nextInt(20000000);
// 채용 공고 조회수 무작위 생성
int viewCount = random.nextInt(5000);
// 채용 공고 제목 설정 (회사 이름 + 포지션 + 모집)
String title = company + " " + position + " 모집";
// CSV 파일에 기록
writer.append(String.valueOf(jobOpeningId)).append(",")
.append(company).append(",")
.append(educationLevel).append(",")
.append(employmentType).append(",")
.append(hiringEndAtStr).append(",")
.append(hiringStartAt).append(",")
.append(jobOpeningUrl).append(",")
.append(location).append(",")
.append(String.valueOf(maxExperienceYears)).append(",")
.append(String.valueOf(minExperienceYears)).append(",")
.append(String.valueOf(salary)).append(",")
.append(title).append(",")
.append(String.valueOf(viewCount)).append(",")
.append(position).append("\n");
}
log.info("CSV 파일 생성 성공");
} catch (IOException e) {
log.error("파일 생성 중 오류 발생: {}", String.valueOf(e));
}
}
}package com.project.cheerha.common.generator;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.List;
import java.util.ArrayList;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class UserKeywordGenerator {
public static void main(String[] args) {
int userCount = 2000; //생성할 사용자 수
int keywordCount = 45; // 전체 키워드 수
Random random = new Random();
// Random 객체로 무작위 값 생성
int idCounter = 1;
// 각 행의 고유 식별자, 일명 id 값
try (FileWriter writer = new FileWriter("user_keywords.csv")) {
// CSV 헤더 작성
writer.append("id,user_id,keyword_id\n");
// 사용자(user_id)마다 무작위로 키워드 선택
for (int userId = 1; userId <= userCount; userId++) {
// 1개에서 최대 45개까지 무작위로 키워드 선택
int numKeywords = random.nextInt(keywordCount) + 1;
// 키워드 리스트 생성 후 무작위로 섞기
List<Integer> allKeywords = new ArrayList<>();
for (int i = 1; i <= keywordCount; i++) {
allKeywords.add(i);
}
// 키워드를 무작위로 섞음
java.util.Collections.shuffle(allKeywords, random);
// 중복 없는 키워드 선택
// 예) 키워드 1,1,4,5가 선택되지 않게 Set 사용
Set<Integer> selectedKeywords = new HashSet<>();
for (int i = 0; i < numKeywords; i++) {
selectedKeywords.add(allKeywords.get(i));
}
// CSV 파일에 기록
for (Integer keywordId : selectedKeywords) {
writer.append(String.valueOf(idCounter)).append(",")
.append(String.valueOf(userId)).append(",")
.append(String.valueOf(keywordId)).append("\n");
idCounter++; // 고유 식별자 증가
}
}
log.info("CSV 파일 생성 성공");
} catch (IOException e) {
log.error("파일 생성 중 오류 발생: {}", String.valueOf(e));
}
}
}package com.project.cheerha.common.generator;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class JobOpeningKeywordGenerator {
public static void main(String[] args) {
int jobOpeningCount = 10000; // 채용 공고 수
int keywordCount = 45; // 기술 키워드 수
Random random = new Random();
// Random 객체로 무작위 값 생성
try (FileWriter writer = new FileWriter("job_opening_keywords.csv")) {
// CSV 헤더 작성
writer.append("id,job_opening_id,keyword_id\n");
int idCounter = 1;
// 각 행의 고유 식별자, 일명 id값
for (int jobOpeningId = 1; jobOpeningId <= jobOpeningCount; jobOpeningId++) {
// 각 채용 공고에 들어갈 키워드 수를 무작위로 선택
int numKeywords = random.nextInt(6) + 5;
// 키워드는 5개에서 10개 사이 무작위로 선택
// 키워드가 중복되지 않도록 Set 사용
Set<Integer> keywords = new HashSet<>();
// 선택된 키워드가 5개에서 10개 사이가 될 때까지 반복
while (keywords.size() < numKeywords) {
int keywordId = random.nextInt(keywordCount) + 1;
keywords.add(keywordId);
}
// CSV 파일에 기록
for (Integer keywordId : keywords) {
writer.append(String.valueOf(idCounter)).append(",")
.append(String.valueOf(jobOpeningId)).append(",")
.append(String.valueOf(keywordId)).append("\n");
idCounter++; // 고유 식별자 증가
}
}
log.info("CSV 파일 생성 성공");
} catch (IOException e) {
log.error("파일 생성 중 오류 발생: {}", String.valueOf(e));
}
}
}처음이라 헤매긴 했지만, CSV(Comma-Separated Values) 파일 생성기(generator)를 여러 개 만들어서 원하는 조건을 넣어서 마음에 드는 더미 데이터를 얻을 수 있었다. 나중에 더 많은 더미 데이터가 필요하다면 조건만 수정하면 원하는 데이터를 얻을 수 있으니 지금 생성기를 만들어두길 잘했다는 생각이 들었다.
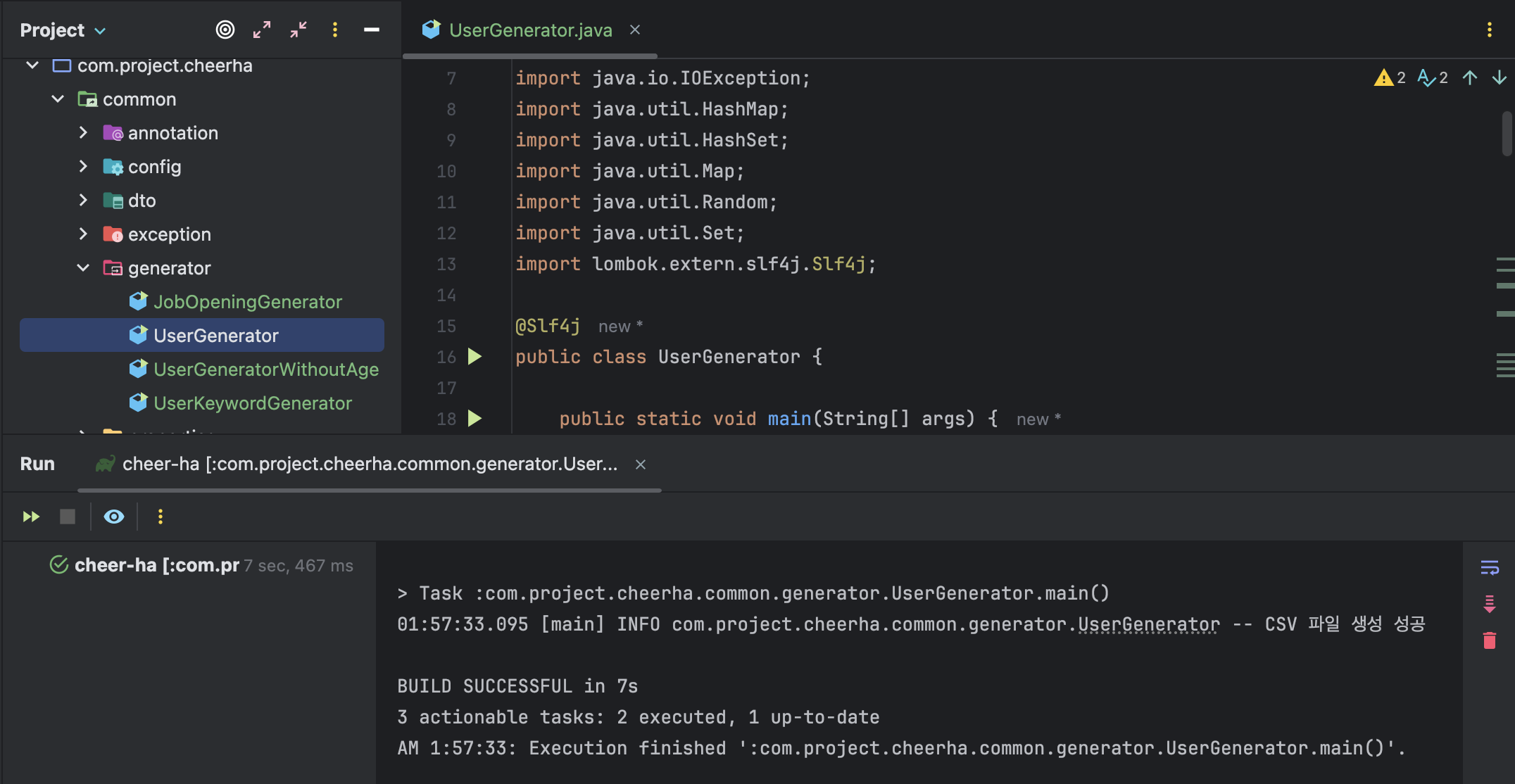
▲ 생성기를 만든 다음에는 실행 버튼을 누르면 CSV 파일이 생겼다.
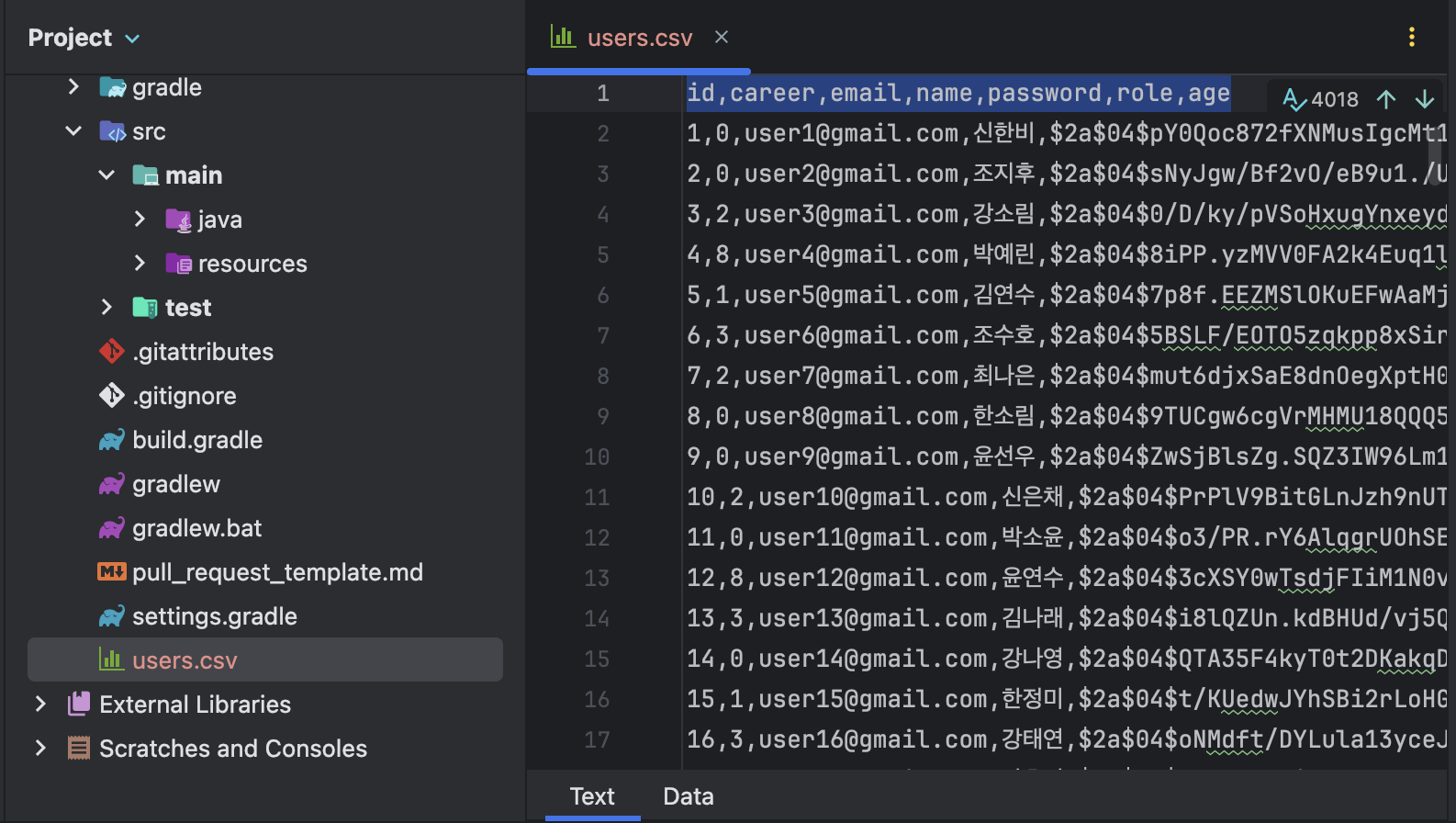
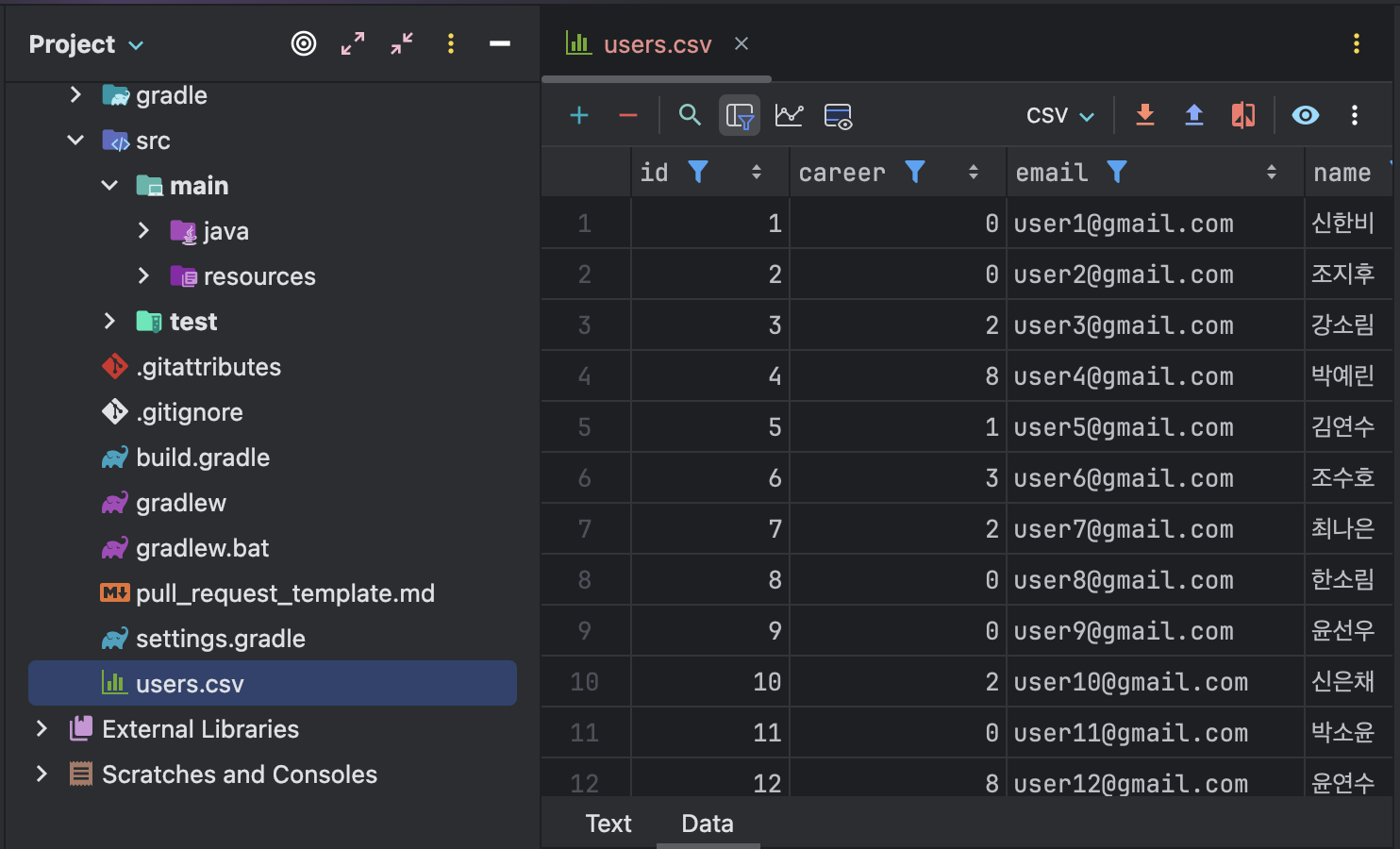
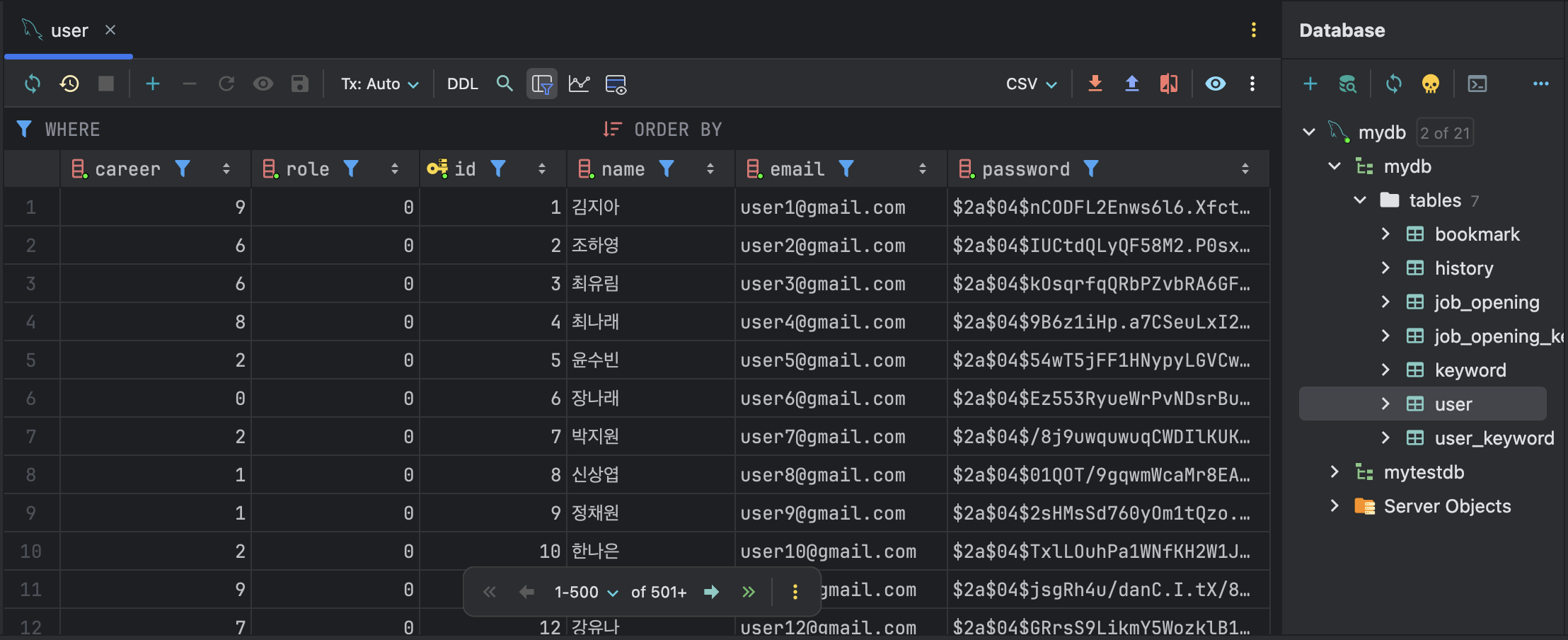
▲ 생성된 CSV 파일은 왼쪽과 같이 텍스트로 보거나 오른쪽과 같이 표로 볼 수 있었다. 맨 위에 적힌 각 열(column)의 이름이 바로 헤더(header)에 해당했다. 이 헤더가 있으면 SQL 같은 다른 프로그램에서 CSV 파일을 읽을 때 헤더로 열의 이름을 자동으로 인식해서 데이터를 삽입했다.
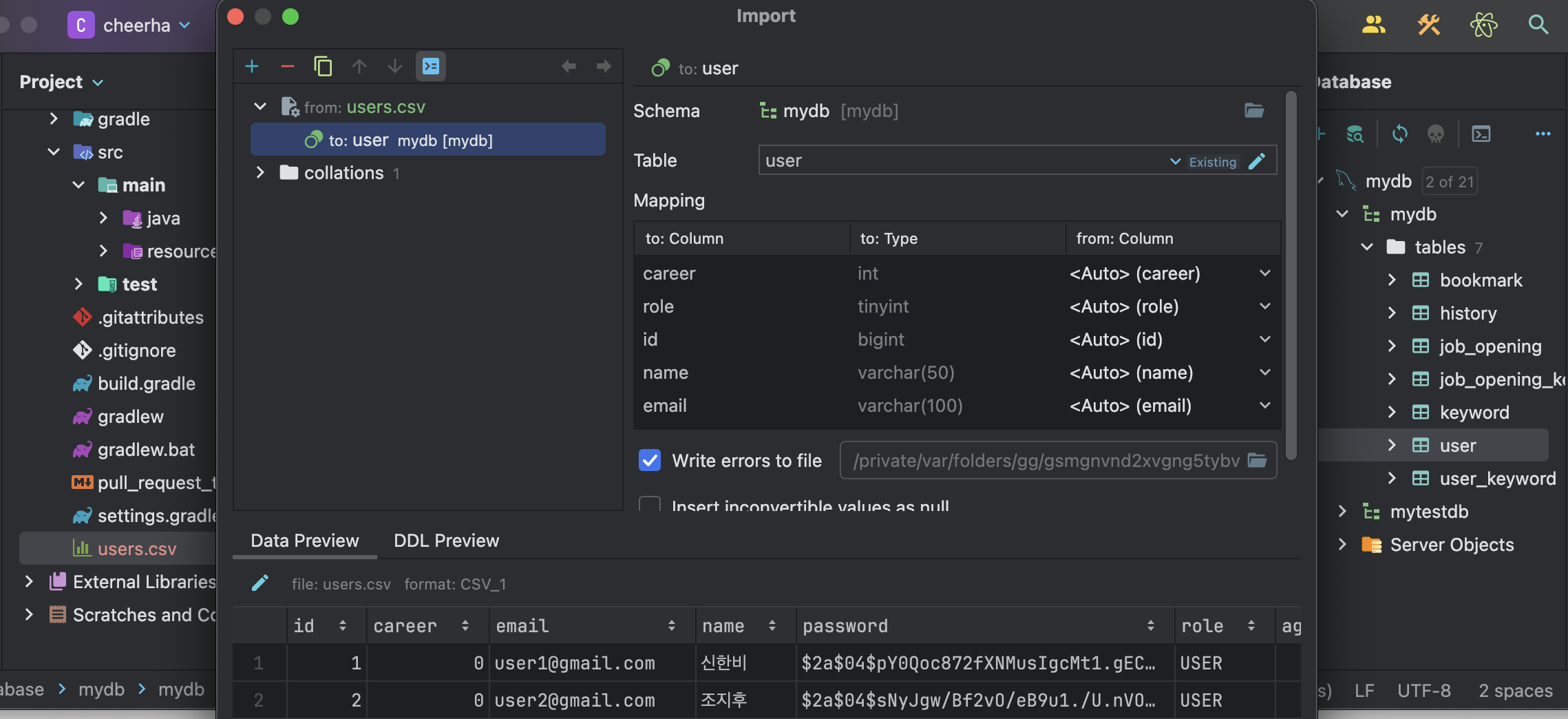
▲ 만들어진 CSV 파일을 데이터베이스의 테이블로 끌고 오면 사진 속 Import 창이 나타났다. 'Data Preview'로 각 데이터가 적절한 열에 들어가는지 확인하면 더미 데이터 삽입이 끝났다.
▲ 이제는 테스트할 때마다 이 많은 데이터를 만들어달라고 챗GPT를 조르지 않아도 되었다.

@SuppressWarnings({"rawtypes", "unchecked"})
public static void shuffle(List<?> list, Random rnd) {
int size = list.size();
// 리스트 크기 저장
if (size < SHUFFLE_THRESHOLD || list instanceof RandomAccess) {
// 리스트 크기가 작거나 RandomAccess 인터페이스를 구현했을 때
for (int i = size; i > 1; i--) {
// 리스트 끝에서 두 번째 요소까지 순회하며 무작위로 요소 교환
swap(list, i - 1, rnd.nextInt(i));
// 0부터 i-1까지 범위에서 무작위로 인덱스를 선택해 교환
}
} else {
// RandomAccess가 아닐 때
// 예시: LinkedList
Object[] arr = list.toArray();
// 리스트를 배열로 변환
for (int i = size; i > 1; i--) {
// 배열을 섞음
swap(arr, i - 1, rnd.nextInt(i));
// 배열 끝에서 순회하며 무작위로 요소를 교환
}
// 섞인 배열을 다시 리스트에 덮어 씀
ListIterator it = list.listIterator();
for (Object e : arr) {
it.next(); // 리스트를 하나씩 이동
it.set(e); // 현재 위치에 배열의 요소를 설정
}
}
}더미 데이터를 만들면서 사용한 김에 shuffle() 메서드가 어떻게 동작하는지 간단하게 정리했다. 내일부터는 온 집중력을 쏟아 이메일 전송 기능을 구현해야 한다. 그다음에 작업해야 할 실시간 알림 기능 구현이 악명 높기로 자자해서 걱정이 산더미이지만, 생각 전환 속도가 느려서 기획 고민에 시간이 오래 걸리지만, 언제 어떤 내용을 담아 어떤 수단으로 알림을 보낼지 고민하는 시간이 썩 나쁘지 않다.
몇 년 동안 글쓰기로 창작의 고통에 익숙해져서 그런가.

여태까지 들은 피드백 중 둥근 원과 가장 거리가 먼 토론의 장 한복판에서,
탁구처럼 피드백이 쉴 새 없이 왔다 갔다 해서 'ping pong'이라 부르나 싶은 지금,
개발자라는 직업이 적성에 맞지 않는 게 아니라, 그런 분위기가 어색할 뿐이라는 위안이 든다.


팀 프로젝트 이름이 'cheerha'라서 이름을 볼 때마다 취업에 성공한 사람들이 다 같이 '짠!' 하는 느낌이 들었다. 오늘 고생한 만큼 코드 말고 로고를 만들어 보고 싶어서 몇 분 동안 부스럭거렸다. 귀여운 그림을 보고 힘내서 내일도 열심히 앞으로 나아가야겠다.
'끝을 보는 용기' 카테고리의 다른 글
| Day 133 - 취하여(취업을 위하여) 프로젝트 23%, 감은 잡았으니 남은 일은 실천뿐 (0) | 2025.02.16 |
|---|---|
| Day 132 - 취하여(취업을 위하여) 프로젝트 22%, 갈 길이 구만리지만 그럴싸한 틀을 잡다 (0) | 2025.02.15 |
| Day 130 - 취하여(취업을 위하여) 프로젝트 16%, 프로젝트를 통째로 갈아엎을 위기에서 가까스로 벗어나다 (0) | 2025.02.13 |
| Day 129 - 취하여(취업을 위하여) 프로젝트 12%, 기록 조금 고민 조금 검토 조금 하니 하루가 다 갔다 (0) | 2025.02.12 |
| Day 128 - 취하여(취업을 위하여) 프로젝트 8%, 어쩐지 해보고 싶더라니 핵심 기능을 골라버렸네 (0) | 2025.02.11 |